Lecture 02: General Linear Model
Descriptive Statistics and Basic Statistics
2024-08-26
Homework 0
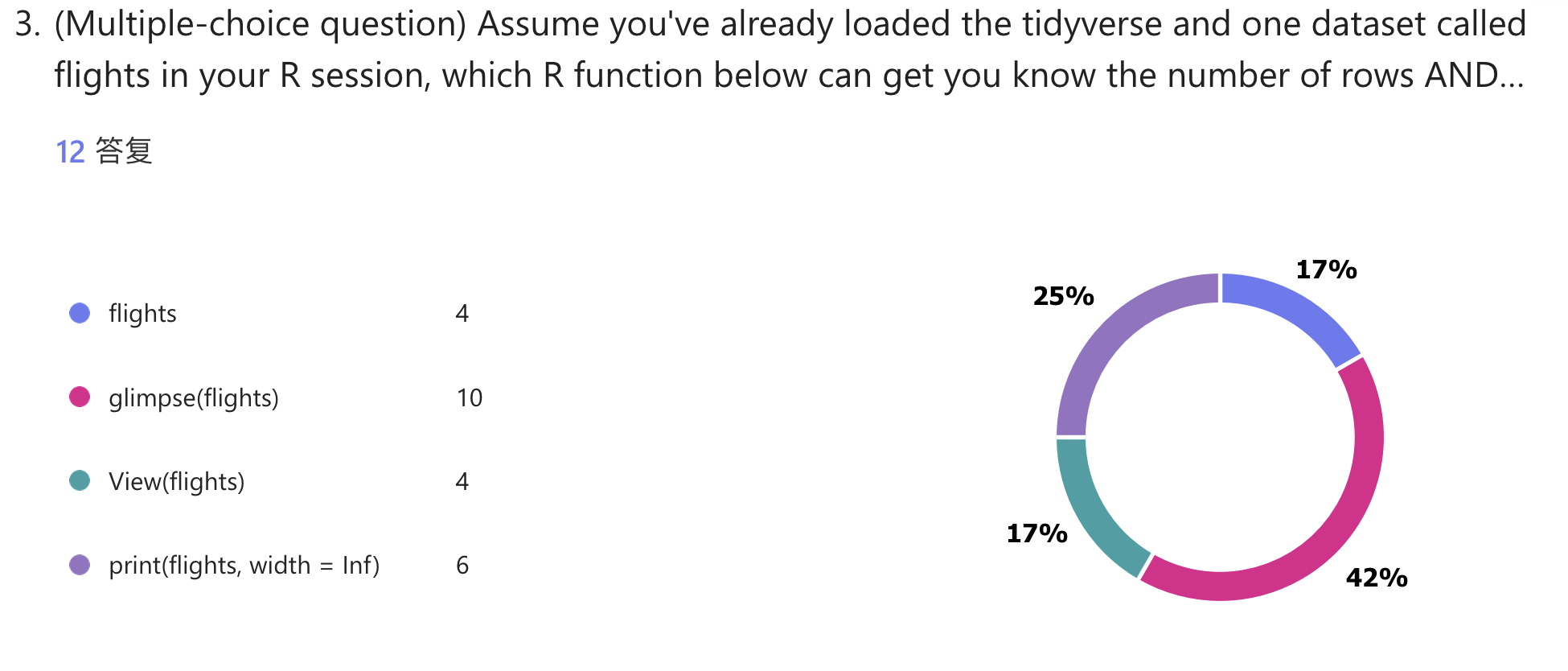
Question 3
Quick Inspect: Distribution of Categorical Variable
FALSE TRUE
10 10 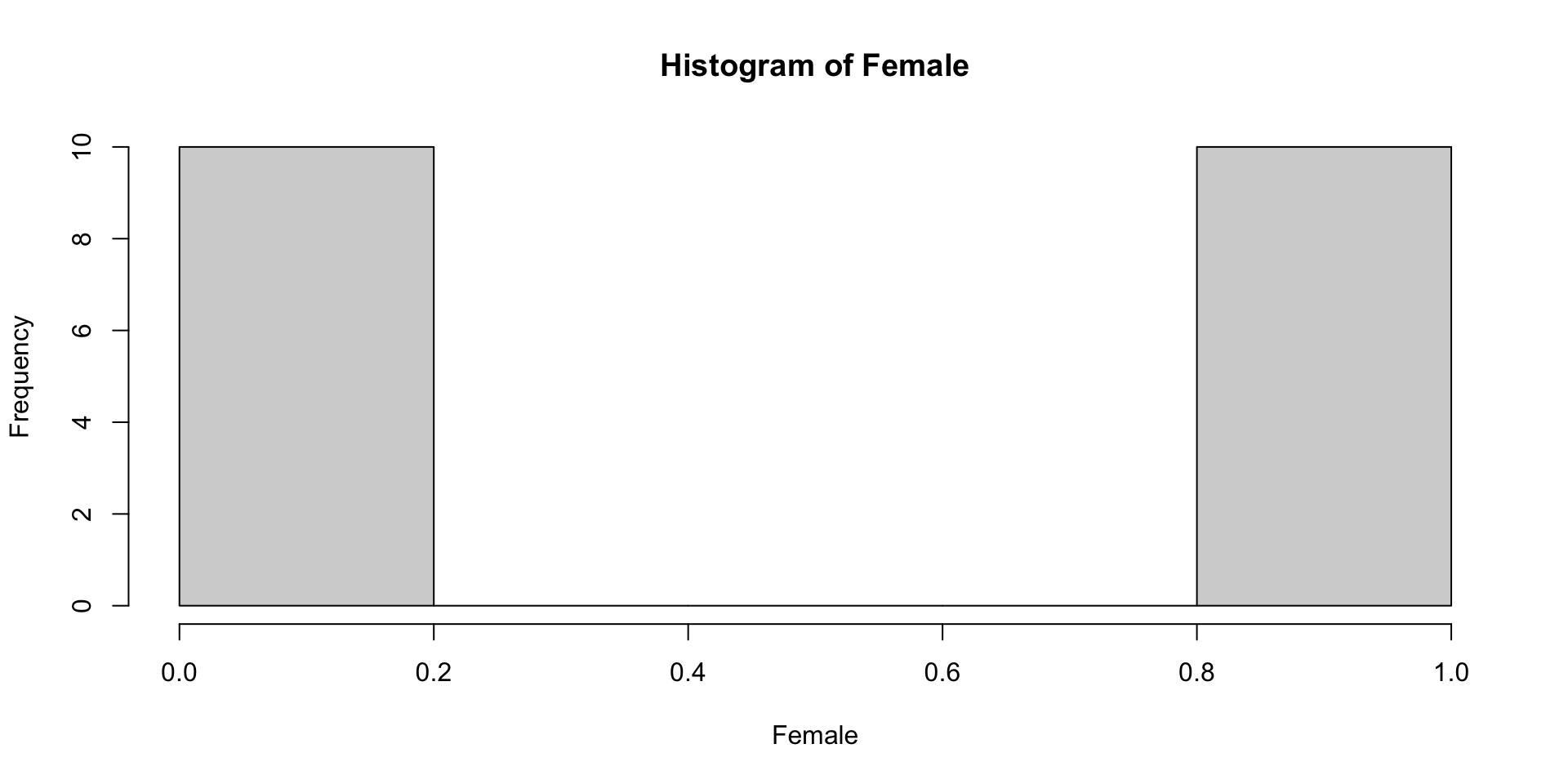
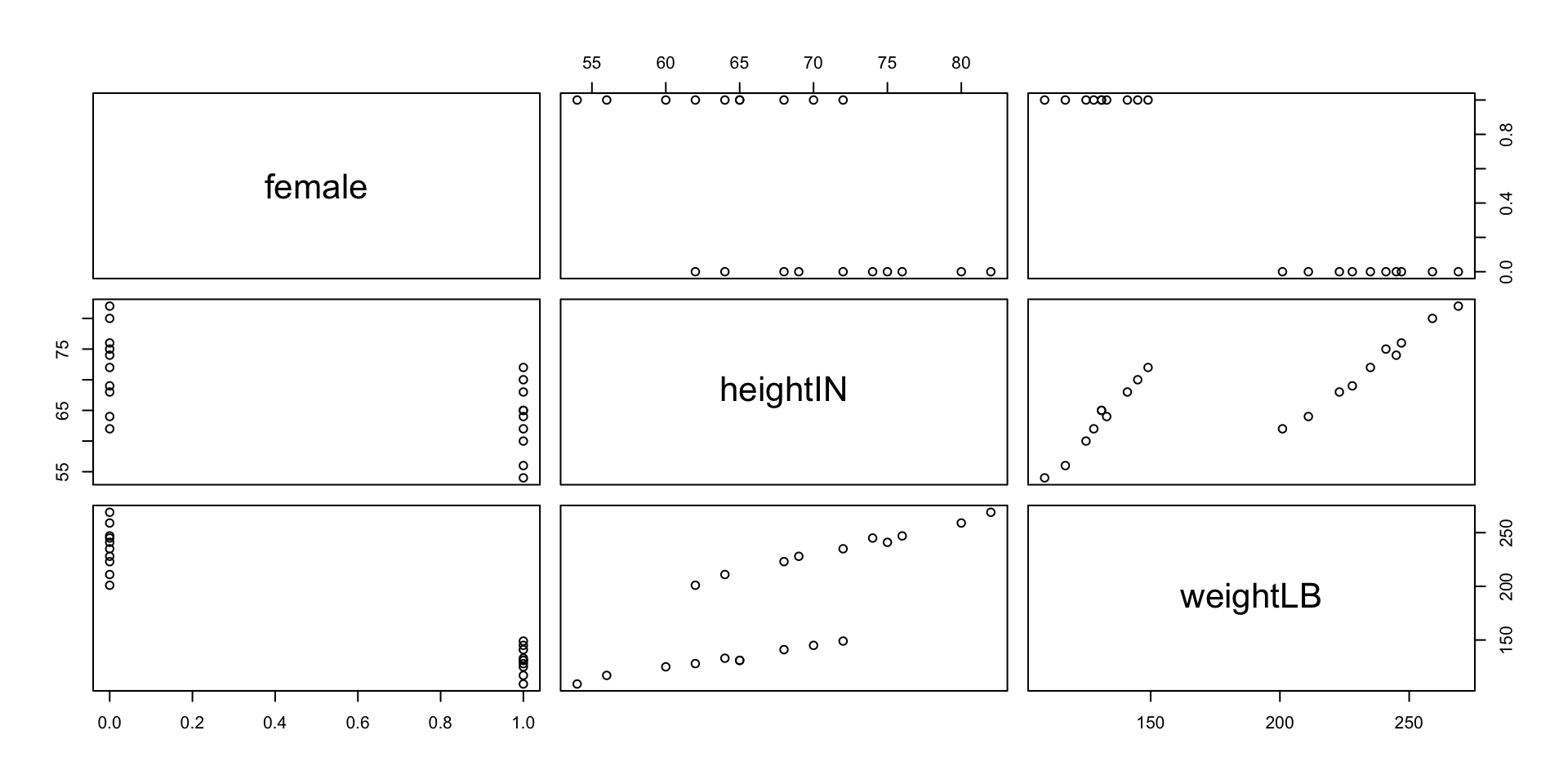
Visualization: Pairwise Scatterplot
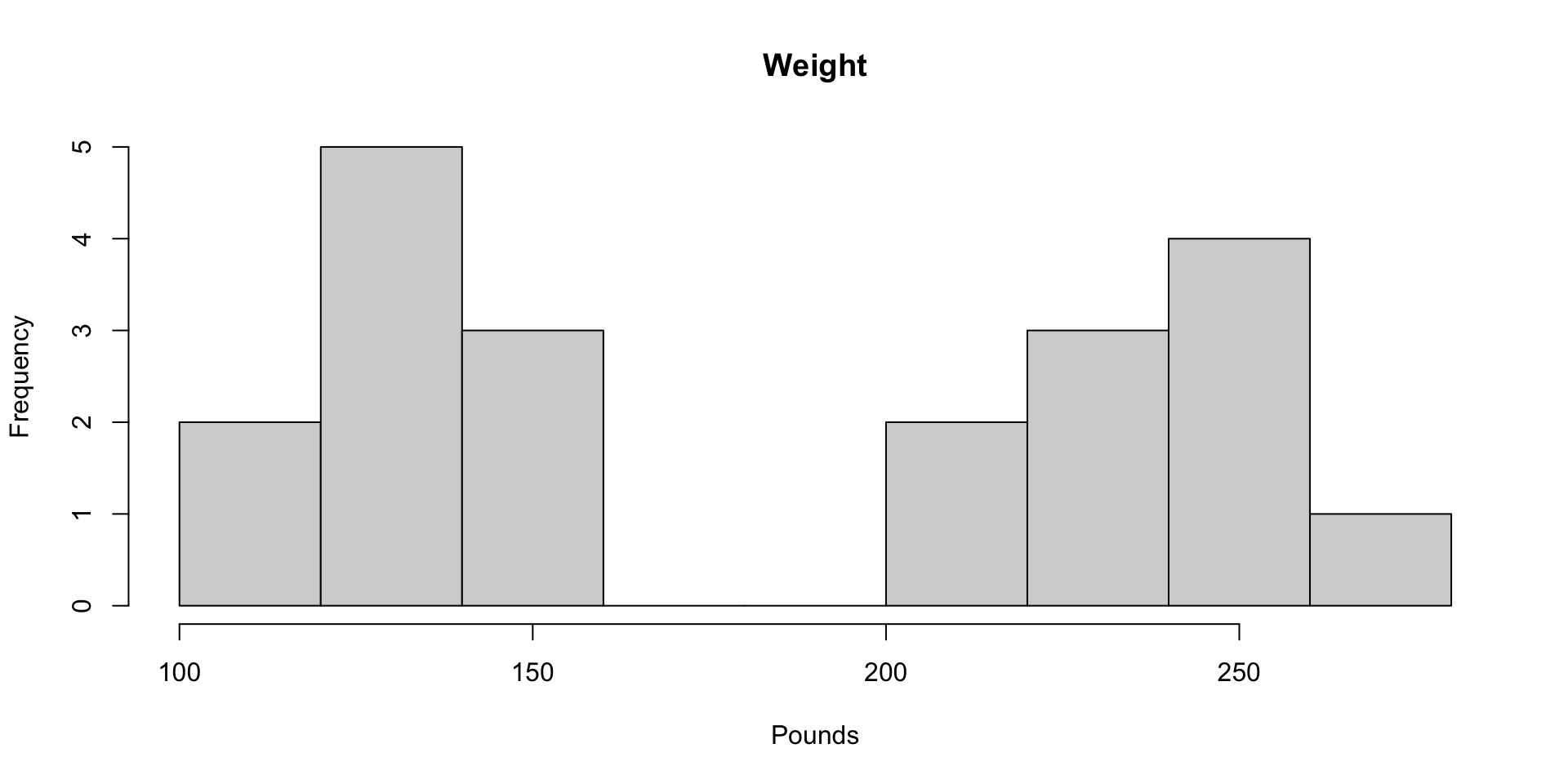
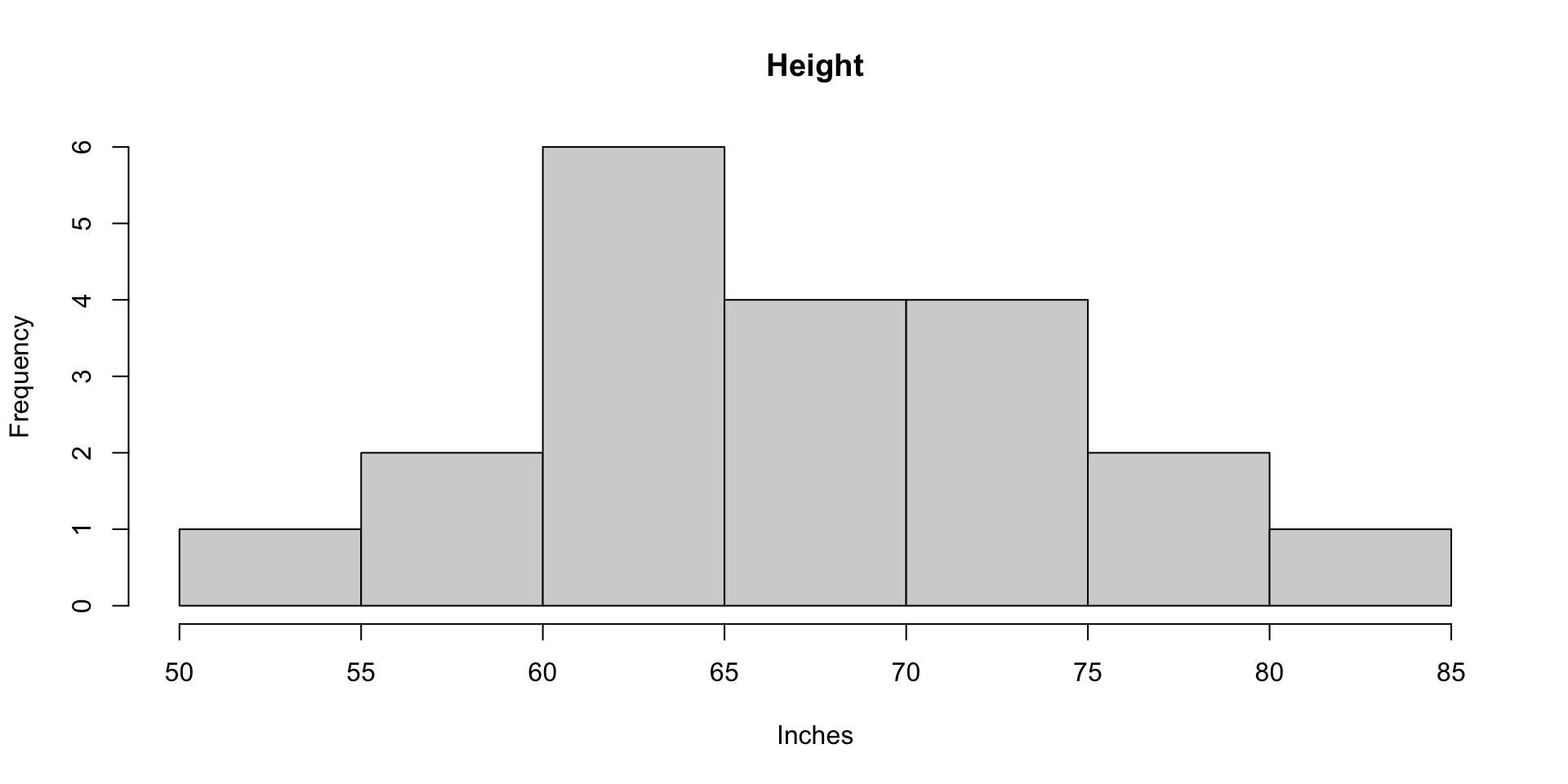
Histograms of Height and Weight
Biased VS. Unbiased Estimator of Variance (Cont.)
Code
library(ggplot2)
variance_mat |>
as.data.frame() |>
pivot_longer(-sample_size) |>
ggplot() +
geom_point(aes(x = sample_size, y = value, color = name), linewidth = 1.1) +
geom_line(aes(x = sample_size, y = value, color = name), linewidth = 1.5) +
labs(x = "Sample Size (N)", y = "Estimates of Variance") +
scale_color_manual(values = 1:3, labels = c("Population Variance", "Sample Biased Variance (ML)", "Sample Unbiased Variance"), name = "Estimator") +
scale_x_continuous(breaks = seq(10, 200, 10)) +
theme_classic() +
theme(text = element_text(size = 25)) 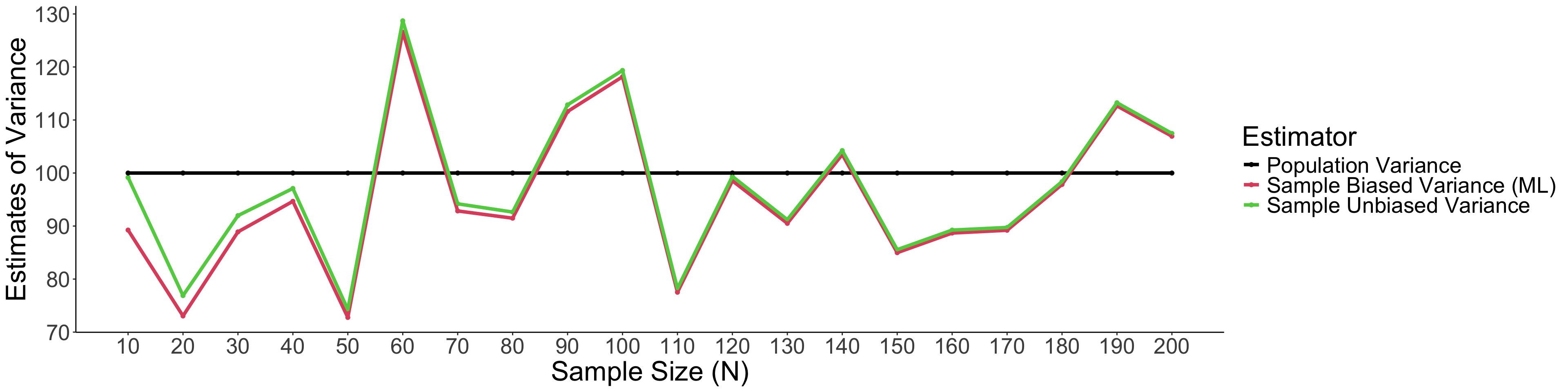
Take home note: When sample size is small, unbiased variance estimators can get the estimate of variance closer to the population variance than the biased one.
Example: Table of Descriptive Statistics
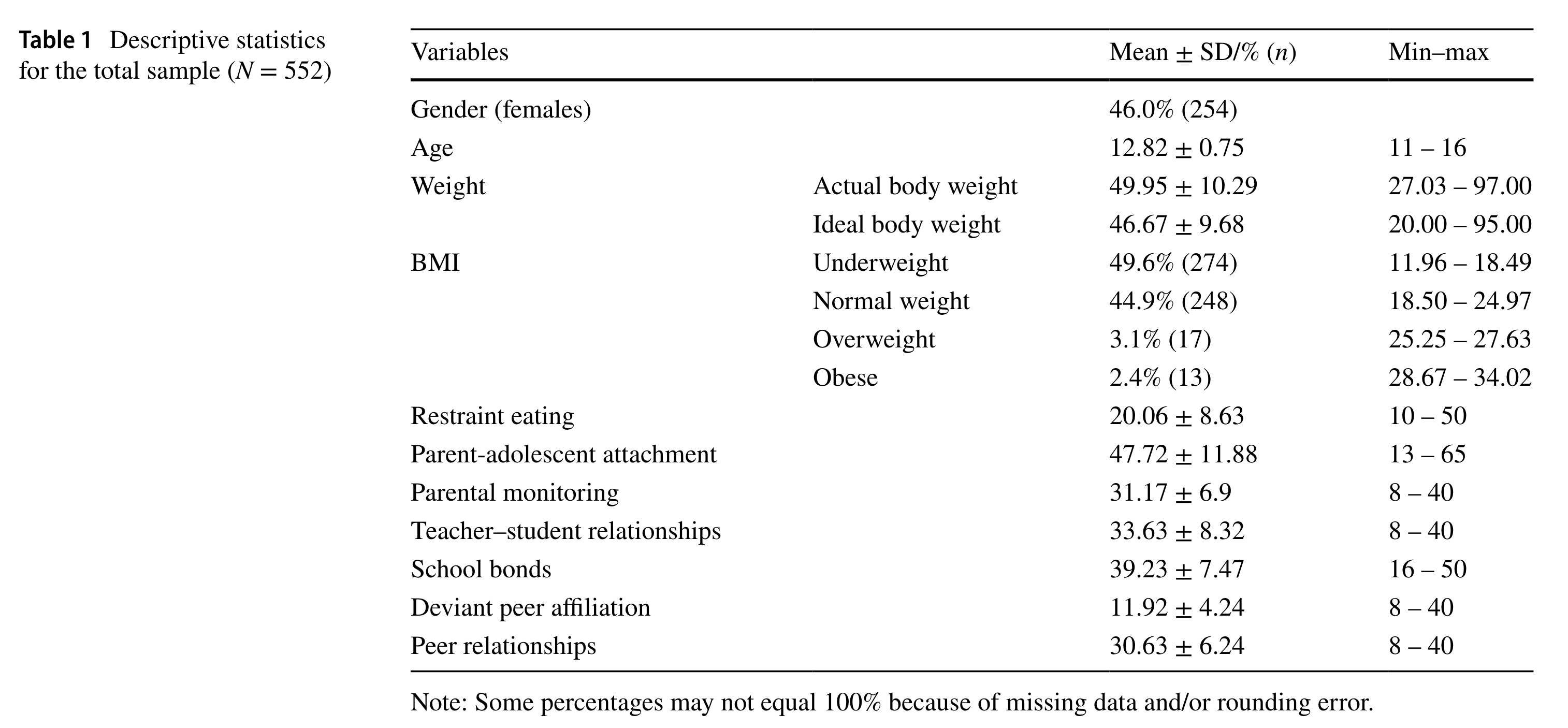
Table 1 (Xiong et al., 2023)
Visualization
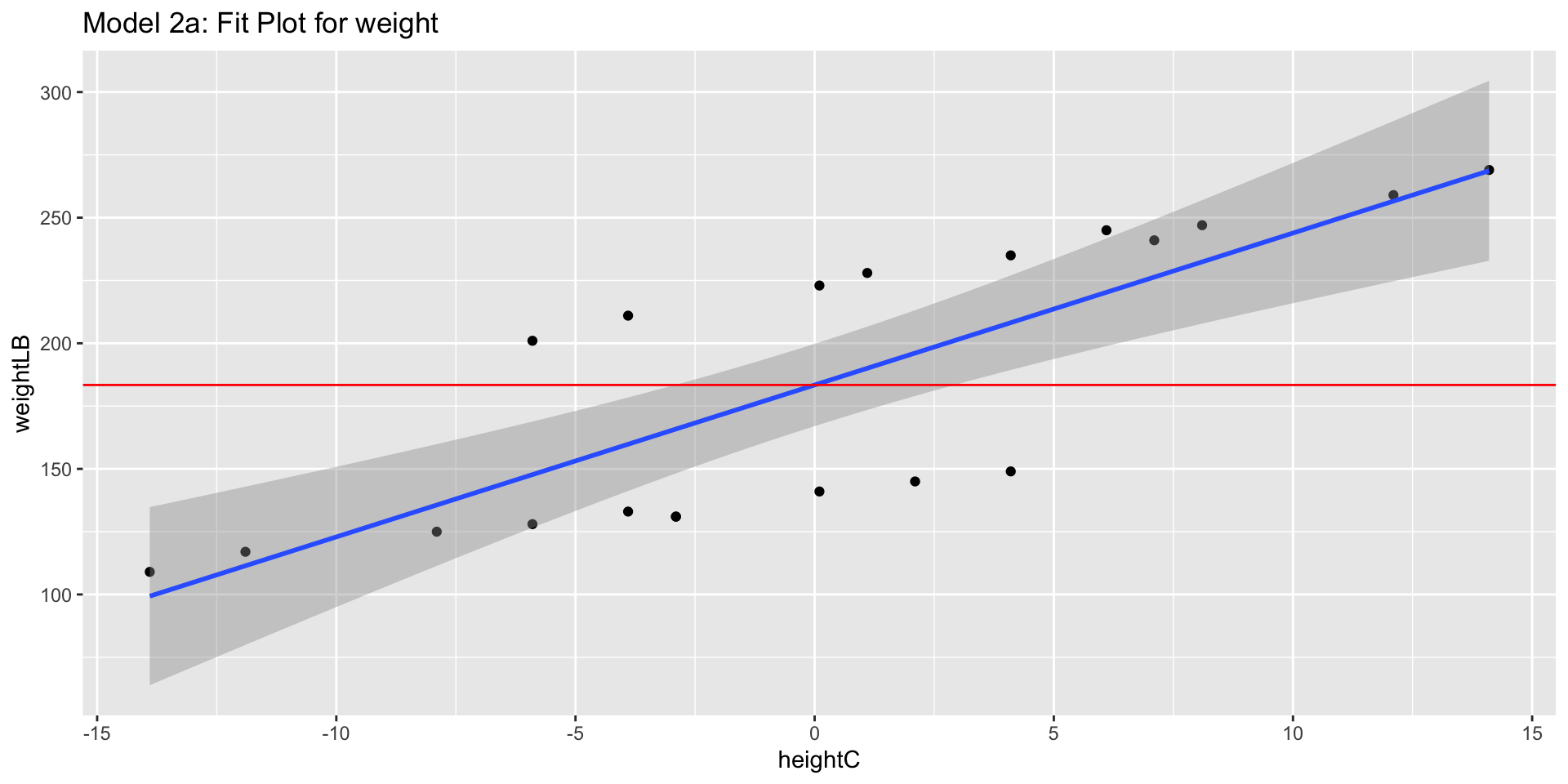
Visualization:
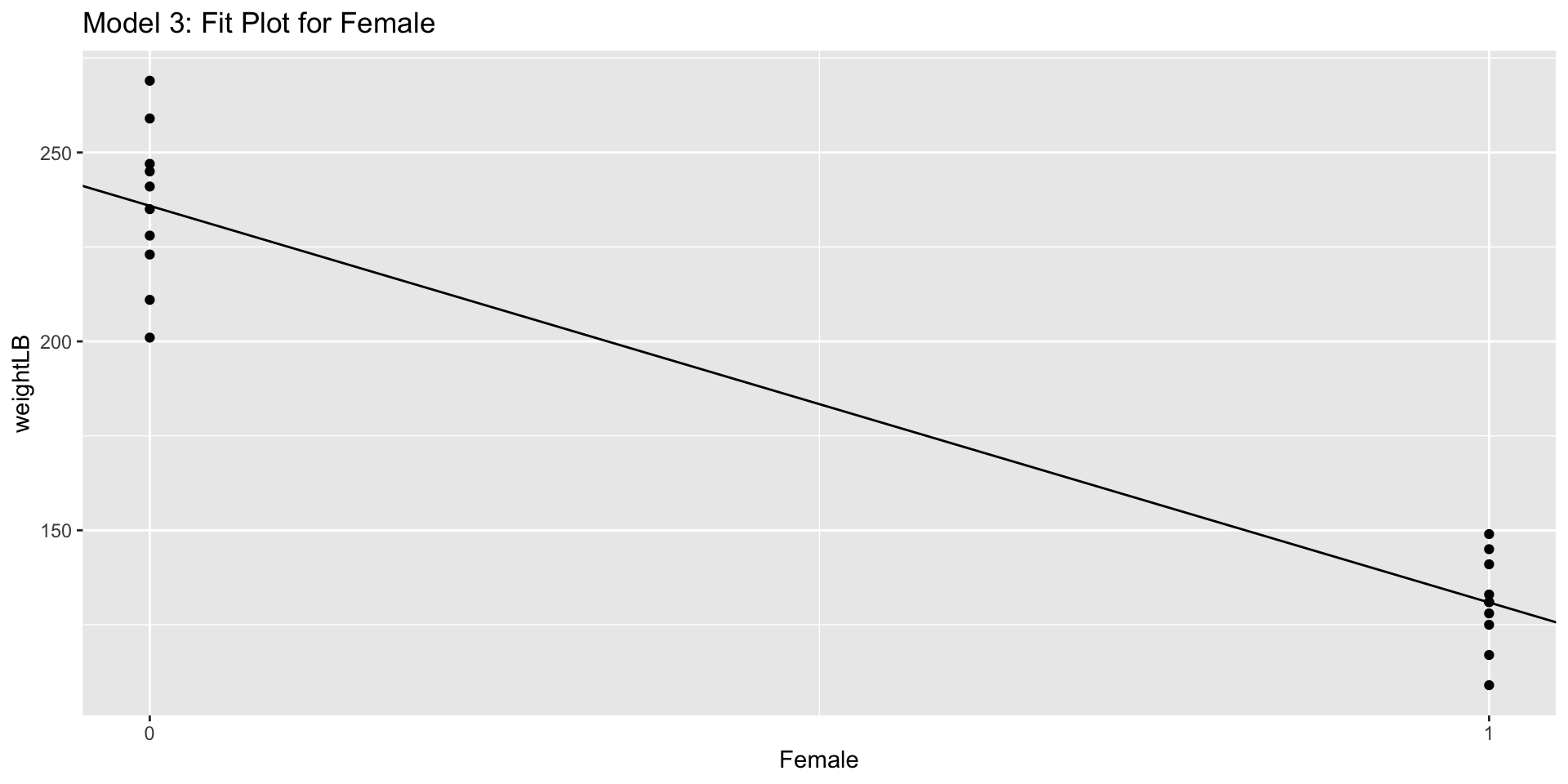
Line Plot (not frequently used in this case)
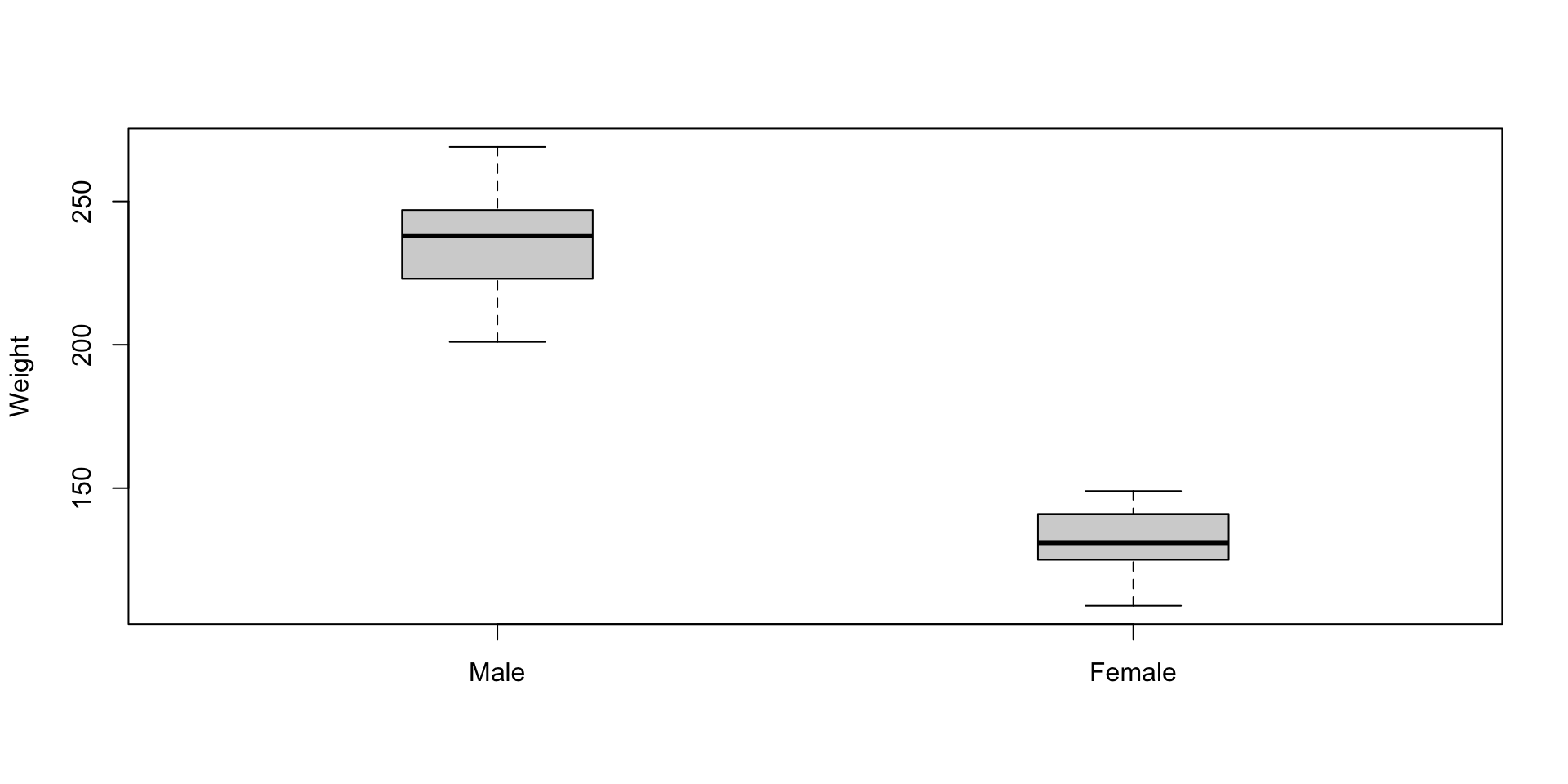
Visualization: box-and-whisker plot (Basic Way)
Visualization: box-and-whisker plot (Fancy Way)
ggplot2 package
ggplot(dataSexHeightWeight, aes(x = female, y = weightLB)) +
geom_dotplot(aes(fill = female, color = female), binaxis='y', stackdir='center') +
stat_summary(fun.data= "mean_cl_normal", fun.args = list(conf.int=.75), geom="crossbar", width=0.3, fill = "yellow", alpha = .5) +
stat_summary(fun.data= "median_hilow", geom="errorbar", fun.args = list(conf.int=1), width = .1, color="black") + # Mean +- 2SD
stat_summary(fun.data= "mean_sdl", geom="point", shape = 5, size = 3) +
scale_x_discrete(labels = c("Male", "Female")) +
labs(x = "", y = "Weight") +
theme_bw() +
theme(legend.position = "none", text = element_text(size = 20)) 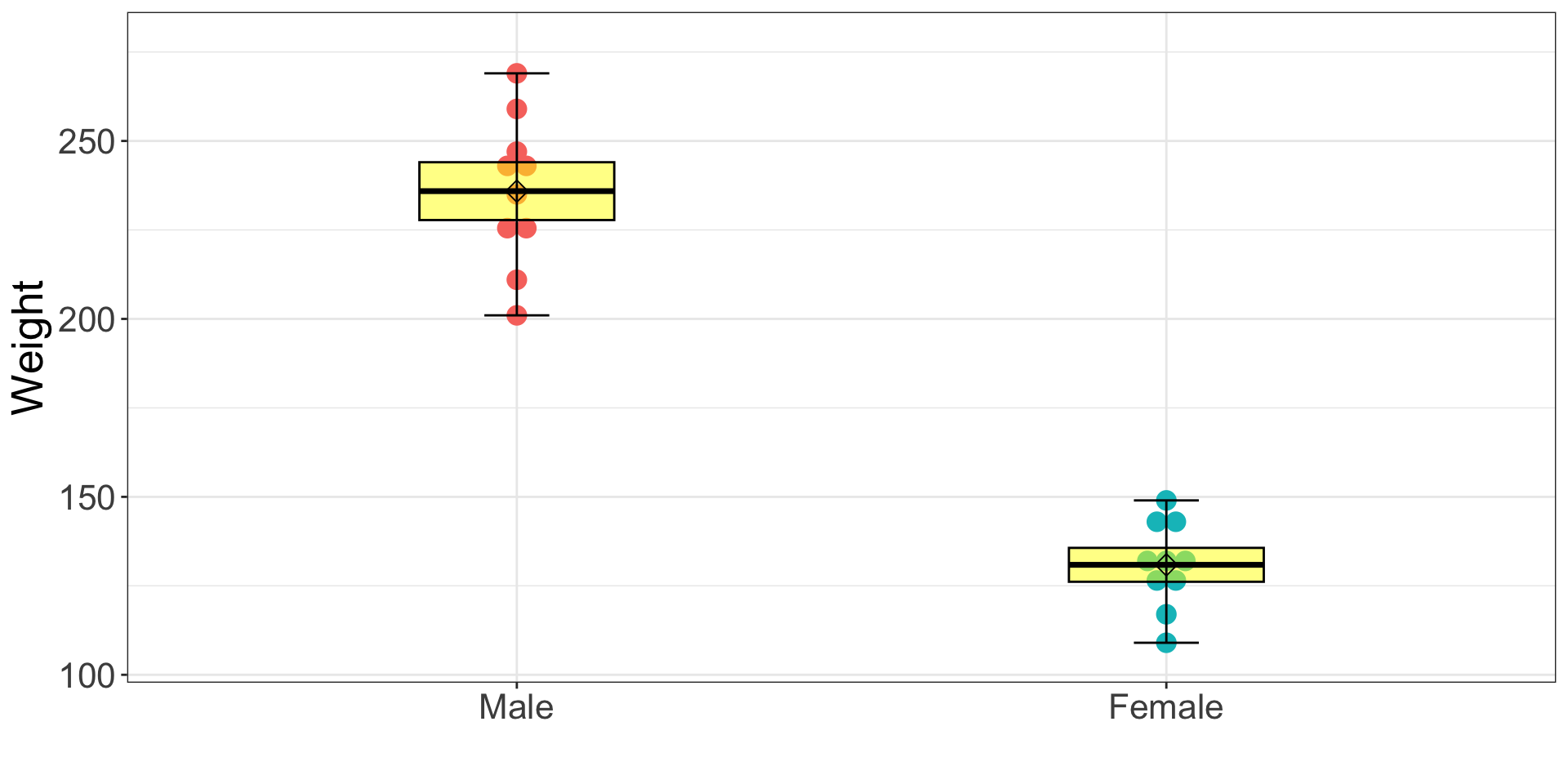
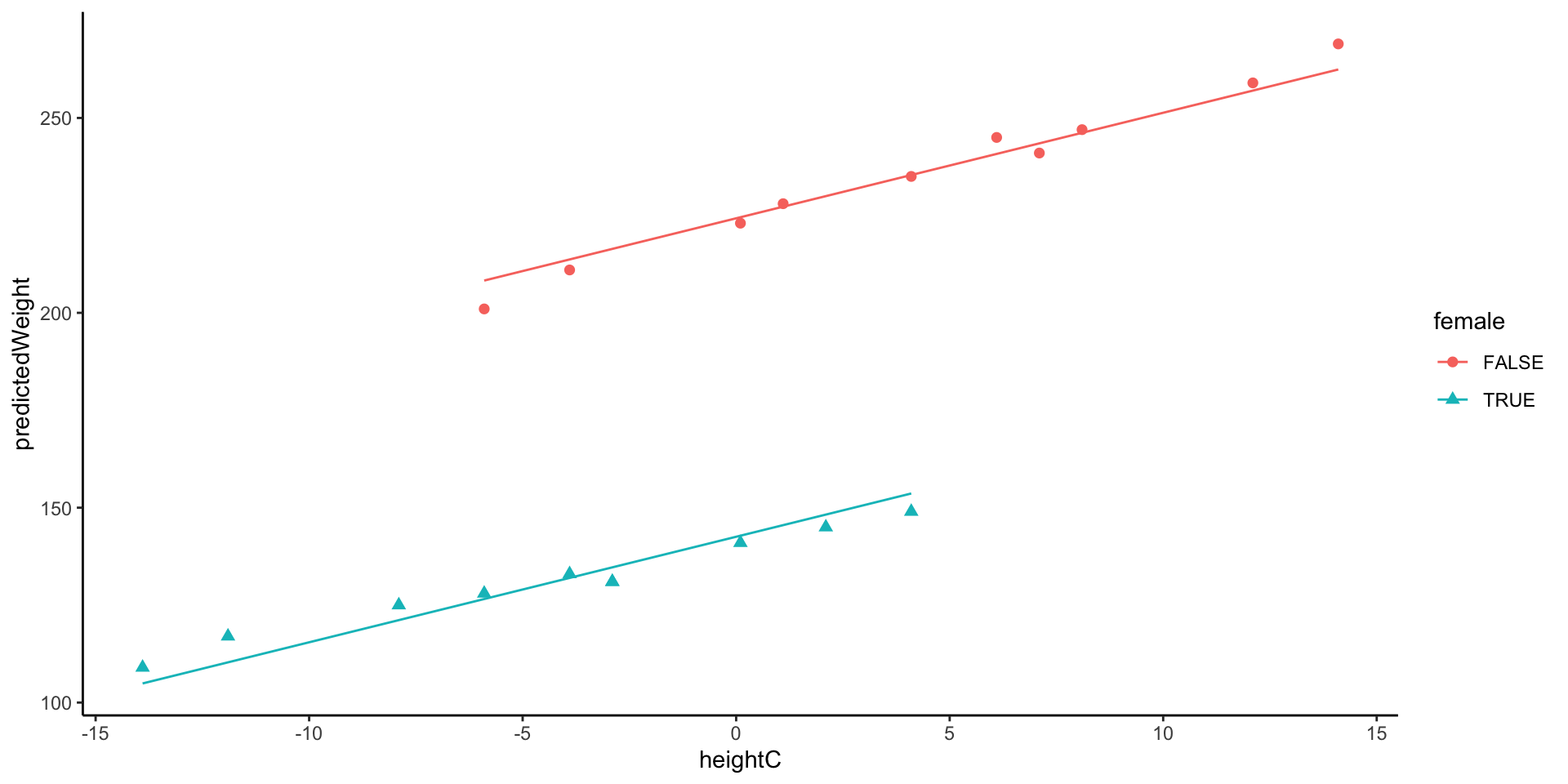
Model 4: By-Gender Regression Lines
Model 4 assumes identical regression slopes for both genders but has different intercepts
- This assumption of different slopes will be tested statistically by model 5
Predicted Weight for Females with the height as 68.9 inch:
\[ W_p=224.256+2.708\times\color{blue}{(68.9-67.9)} - 81.713*\color{red}{1} \\ = 224.256+2.708-81.712 = 145.252 \]
Predicted Weight for Males with the height as 68.9 inch:
\[ W_p=224.256+2.708\times\color{blue}{(68.9-67.9)} - 81.713*\color{red}{0} \\ = 224.256+2.708 = 226.964 \]
1
145.252
1
226.9639 Visualization: Different intercept and Same slope across groups
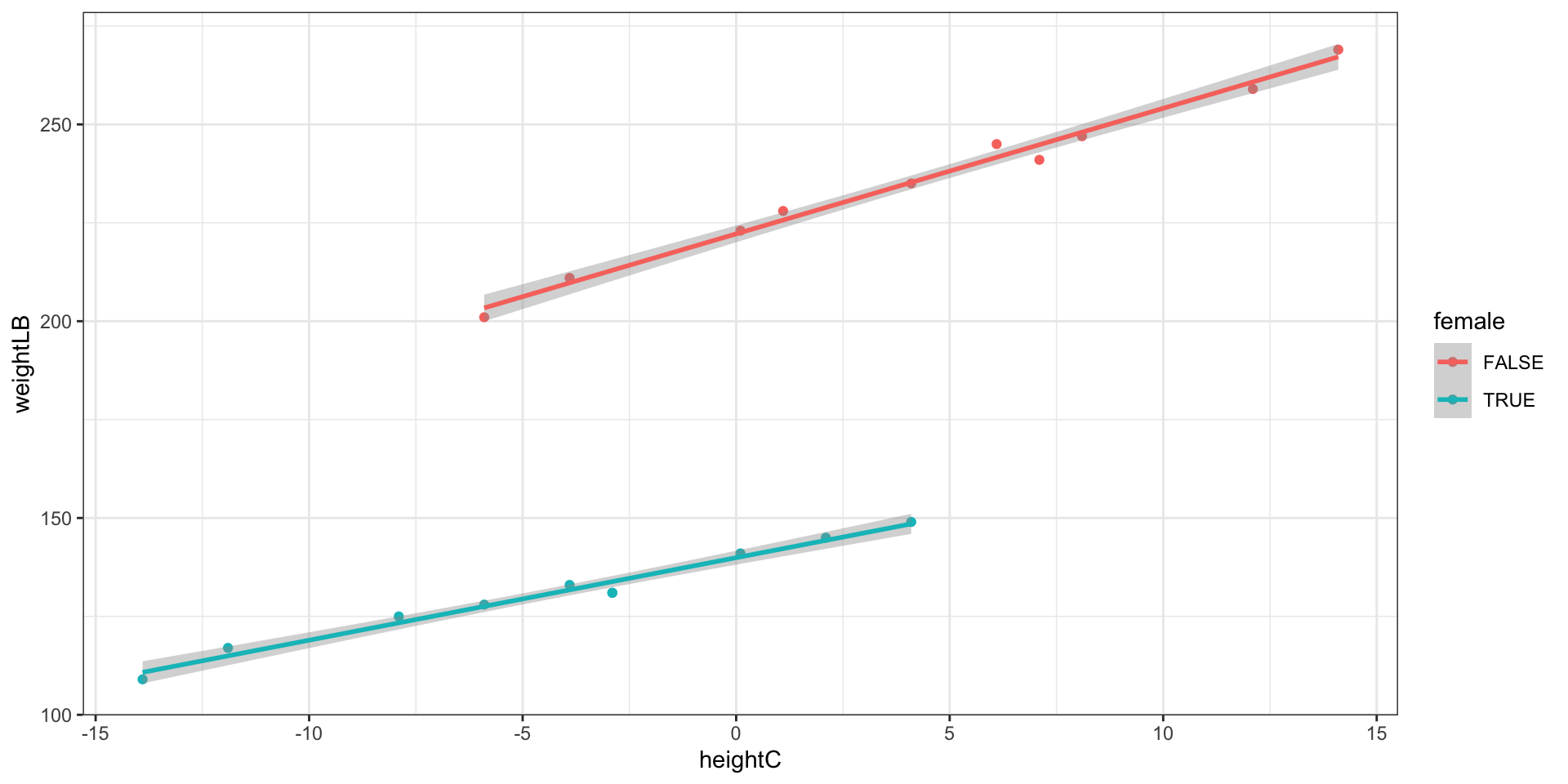
Visualization: Different slopes and different intercepts
Model 5 does not assume identical regression slopes
- Because \(\beta_3\) was significantly different from zero, the data supports different slopes for the gender
Code
get_res_var <- function(model) {
anova(model)$`Mean Sq` |> tail(1)
}
data.frame(
Model = paste("Model", c(1, 2, "2a", 3, 4, 5)),
ResidualVariance = sapply(list(model1, model2, model2a, model3, model4, model5), get_res_var)
) |>
ggplot(aes(x = Model, y = ResidualVariance)) +
geom_point() +
geom_path(group = 1) +
geom_label(aes(label = round(ResidualVariance, 2)),nudge_y = 200, nudge_x = 0.2) +
labs(title = "Estimated Residual Variances across models") +
theme(text = element_text(size = 20))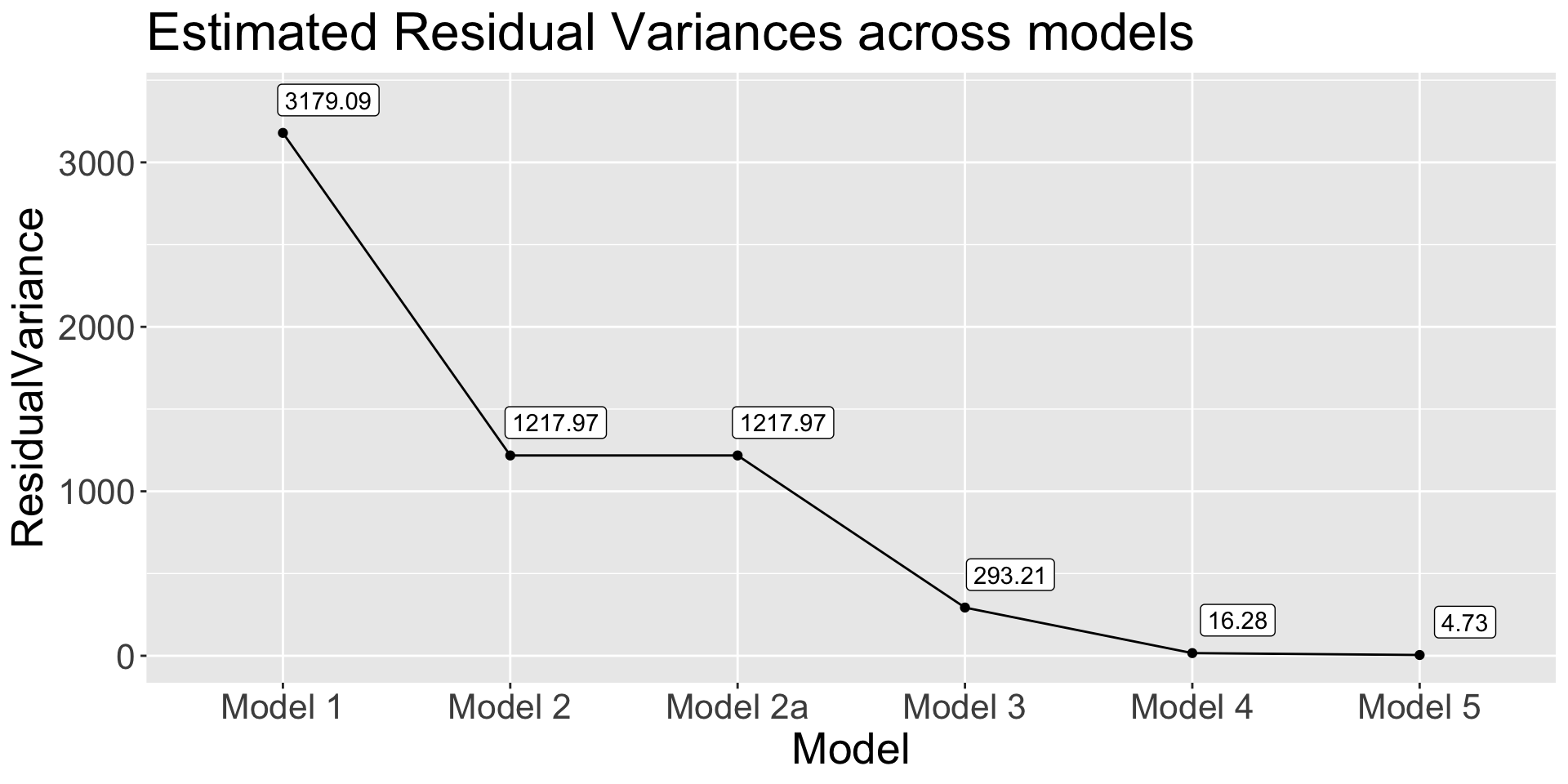
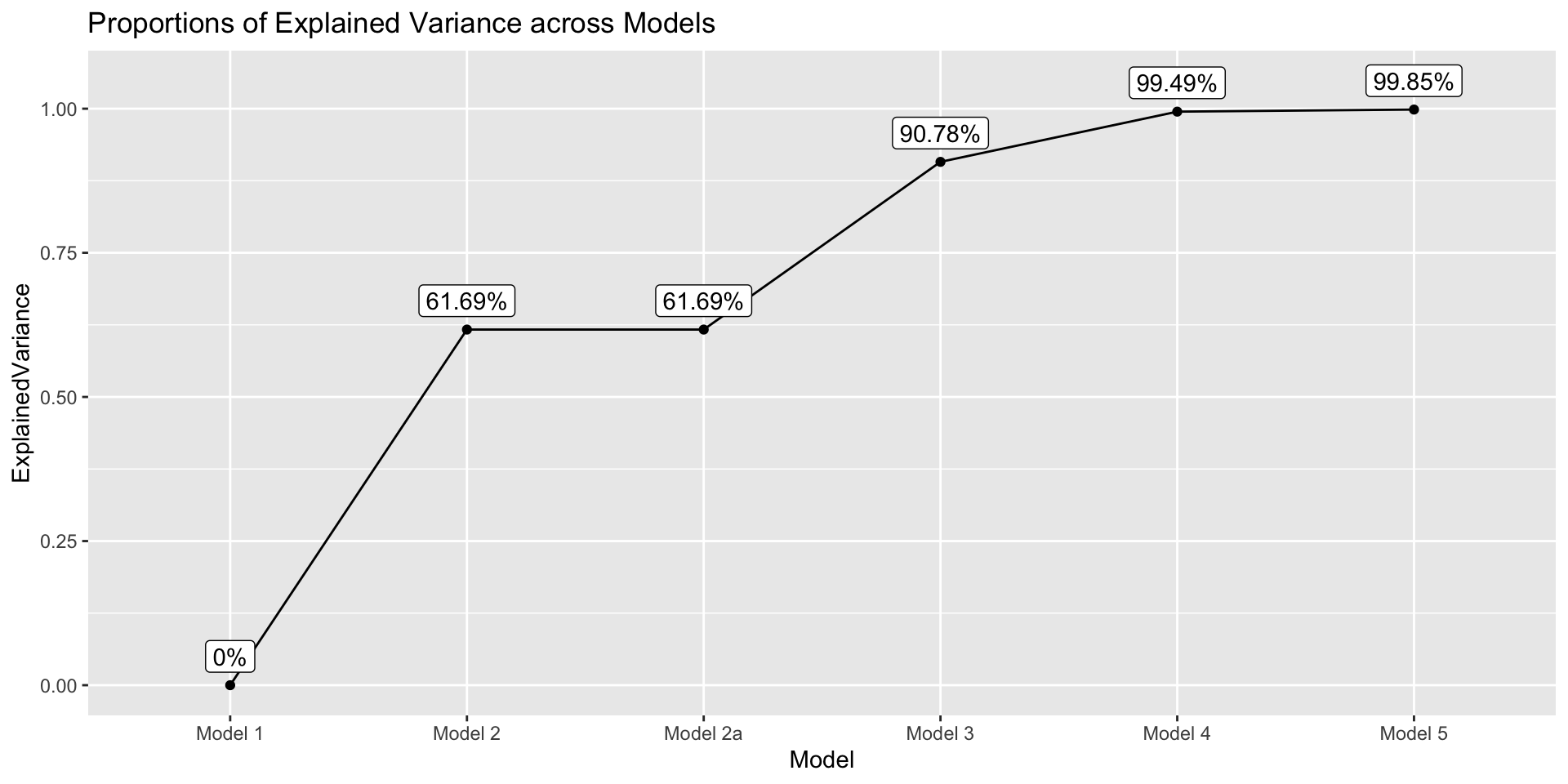
Code
get_explained_var <- function(model) {
tot_err_var <- anova(model1)$`Mean Sq` |> tail(1)
current_err_var <- anova(model)$`Mean Sq` |> tail(1)
prop <- (tot_err_var - current_err_var)/ tot_err_var
prop
}
data.frame(
Model = paste("Model", c(1, 2, "2a", 3, 4, 5)),
ExplainedVariance = sapply(list(model1, model2, model2a, model3, model4, model5), get_explained_var)
) |>
ggplot(aes(x = Model, y = ExplainedVariance)) +
geom_point() +
geom_path(group = 1) +
geom_label(aes(label = paste0(round(ExplainedVariance*100, 2), "%")),nudge_y = .05) +
labs(title = "Proportions of Explained Variance across Models")