Dissertation Defence
TITLE: A novel method for model selection in Bayesian Diagnostic Classification Modeling
Jihong Zhang
University of Iowa
2022-10-24
Outline
Background (5 minutes)
Performance measures (5 minutes)
Simulation study (15 minutes)
Empirical study (10 minutes)
Conclusion (5 minutes)
Discussion (5 minutes)
Backgroud
- Research motivation:
- Why Q-matrix misspecification is a problem?
- The advantages of the proposed method over previous approaches?
- Research objectives
Research Motivation
Q-matrix is usually determined by expert judgement, so there can be uncertainty about some of its elements. Model selection methods are necessary to select the model with the “correct” Q-matrix.
Previous model selection methods such as information criterion and Bayes Factors are not flexible regarding checking specific aspects of data
Posterior predictive checking (PPC)
Advantages of PPC
- PPC is a flexible tool and implemented in most Bayesian software.
Drawbacks of PPC
PPC is not fully Bayesian since it doesn’t take the uncertainty of observed data into account
PPC uses data twice
Research Objectives
To construct a novel PPMC method using limited-information model fit indices in Bayesian LCDM
Simulation study: to determine the performance of the proposed method under different conditions and compare it to previous model checking methods
Empirical study: to investigate the utility of PPMC with limited-information model fit indices in real settings
Overview: Proposed Approach
Performance measures
- Cognitive diagnostic index - item/test discrimination index
- Posterior predictive M2 - absolute fit
- KS-PP-M2 and InfoCrit (AIC/BIC/DIC/WAIC) - relative fit
Simulation Study
Research Questions
Is the proposed method appropriate for detecting model-data misfit with varied degree of Q-matrix misspecification
Compared to information criteria, does the proposed approach have higher true positive rate (TPR) when selecting the correct model?
How does the overall discrimination power indicated by Cognitive Diagnostic Index affects the performance of the proposed method in selecting the model with best Q-matrix?
Simulation Settings
Generate simulated data sets under the LCDM framework with two main factors:
- sample size: 200 draws from 1000 to 2000
- attribute correlation: {0.25, 0.5}
- 400 conditions in total
30 items and 5 attributes
Latent attributes: mastery status of attributes for each individual are determined by cutting attribute scores. Item parameters are randomly sampled.
Based on attribute correlation, continuous attribute scores are first generated for each sample.
Then continuous attribute scores are dichonomized by cutting the scores with the cutting scores
Finally. observed item responses are generated with attribute status and corresponding item parameters
Analysis Models
- Bayesian Network model
- Data generation model - LCDM
- Model with 3 items (10%) underspecify attributes
- Model with 6 items (20%) underspecify attributes
- Model with 3 items (10%) misspecify attributes
- Model with 6 items (20%) misspecify attributes
Q-matrix
library(tidyverse)
QmatPlot <- function(path, model) {
q1 <- read.csv(path)
colnames(q1) <- paste0("A", 1:5)
q1$Col = 0
if(model == 2){
q1[11:13, ] = ifelse(q1[11:13, ] == 1, 3, 0)
}else if(model == 3){
q1[11:13, ] = ifelse(q1[11:13, ] == 1, 3, 0)
q1[21:23, ] = ifelse(q1[21:23, ] == 1, 3, 0)
}else if( model == 4){
q1[1:3, ] = ifelse(q1[1:3, ] == 1, 3, 0)
}else if(model == 5){
q1[1:3,] = ifelse(q1[1:3, ] == 1, 3, 0)
q1[11:13,] = ifelse(q1[11:13, ] == 1, 3, 0)
}
q1_plot <- q1 |>
mutate(Index = 1:n()) |>
pivot_longer(starts_with("A"),
names_to = "Attr",
values_to = "Val") |>
mutate(Val = as.factor(Val),
Index = as.factor(Index),
Col = as.factor(Col))
cbPalette <- c("#999999", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7")
ggplot(q1_plot) +
geom_tile(aes(x = Attr, y = Index, fill = Val, color = Col)) +
labs( x = "", y = "") +
scale_y_discrete(limits=rev) +
scale_x_discrete(position = "top") +
scale_fill_manual(values=cbPalette) +
scale_color_manual(values =c("white", "black")) +
theme(legend.position="none")
}
model1Q <- QmatPlot(path = "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis/Code/true_Q_matrix.csv", model = 1)
model2Q <- QmatPlot(path = "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis/Code/undersp10_Q_matrix.csv", model = 2)
model3Q <- QmatPlot(path = "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis/Code/undersp20_Q_matrix.csv", model = 3)
model4Q <- QmatPlot(path = "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis/Code/incor10_Q_matrix.csv", model = 4)
model5Q <- QmatPlot(path = "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis/Code/incor20_Q_matrix.csv", model = 5)
model1Q
model2Q
model3Q
model4Q
model5Q
# ggpubr::ggarrange(model1Q, model2Q, model3Q, model4Q, model5Q,
# labels = paste("Model", 1:5),
# ncol = 5, nrow = 1)MCMC settings
- All Bayesian models are estimated using blatent R package in R version 3.6
- 4 MCMC with 4000 iterations with first 1000 discarded
- Prior distribution are set up by default of blatent.
- All parameters estimation converged with PSRF < 1.1
Result (Simulation study)
Summary of Posterior Predictive M2 (500 draws)
library(gt)
root <- "~/Library/CloudStorage/OneDrive-Personal/2022_Projects/1_PhD_Thesis"
tab <- read.csv(glue::glue(root, "/Table/Table1_SummaryTablePPMC.csv"))
tab1 <- tab |>
mutate(N_group = case_when(
N < 1250 ~ "[1000,1250)",
N < 1500 ~ "[1250,1500)",
N < 1750 ~ "[1500,1750)",
TRUE ~ "[1750,2000)",
)) |>
group_by(N_group, Rho) |>
summarise(
across(starts_with("mean"), list(mean = mean, sd = sd), .names = "{.col}_{.fn}")
)sumtab1 <- tab1 |>
mutate(Rho = factor(Rho, levels = c(25, 50),
labels = c("Skill Correlation is .25", "Skill Correlation is .50"))) |>
group_by(Rho) |>
gt(rowname_col = "N_group") |>
fmt_number(starts_with("mean"), decimals = 2) |>
cols_merge(
columns = starts_with("mean_BayesNet"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("mean_true"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("mean_undersp10"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("mean_undersp20"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("mean_incor10"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("mean_incor20"),
pattern = "{1}({2})"
) |>
tab_spanner(
label = "Underspecified Qmatrix",
columns = starts_with("mean_undersp")
) |>
tab_spanner(
label = "Incorrect specified Qmatrix",
columns = starts_with("mean_incor")
) |>
cols_label(
N_group = "Sample Size",
mean_BayesNet_mean = "BayesNet",
mean_true_mean = "Correct",
mean_undersp10_mean = "10%",
mean_undersp20_mean = "20%",
mean_incor10_mean = "10%",
mean_incor20_mean = "20%"
) |>
tab_style(
style = cell_text(style = "italic"),
locations = cells_row_groups()
) |>
tab_style(
style = cell_text(weight = "bold"),
locations =
list(
cells_body( # smaller value for correct model
columns = mean_true_mean,
rows = N_group %in% c("[1000,1250)", "[1250,1500)") | round(mean_true_mean, 2) == 38.30
),
cells_body( # smaller value for BayesNet model
columns = mean_BayesNet_mean,
rows = N_group == "[1750,2000)" | round(mean_BayesNet_mean, 2) == 43.38
)
)
) |>
tab_footnote(
footnote = "Bold font: The model with smallest average values of PP-M2.",
locations =
cells_column_labels( # smaller value for correct model
columns = mean_true_mean
)
) |>
data_color(
columns = starts_with("mean"),
colors = scales::col_numeric(
palette = "BuPu",
domain = c(1, 120)
)
) |>
as_raw_html()
sumtab1Path plot for PP-M2
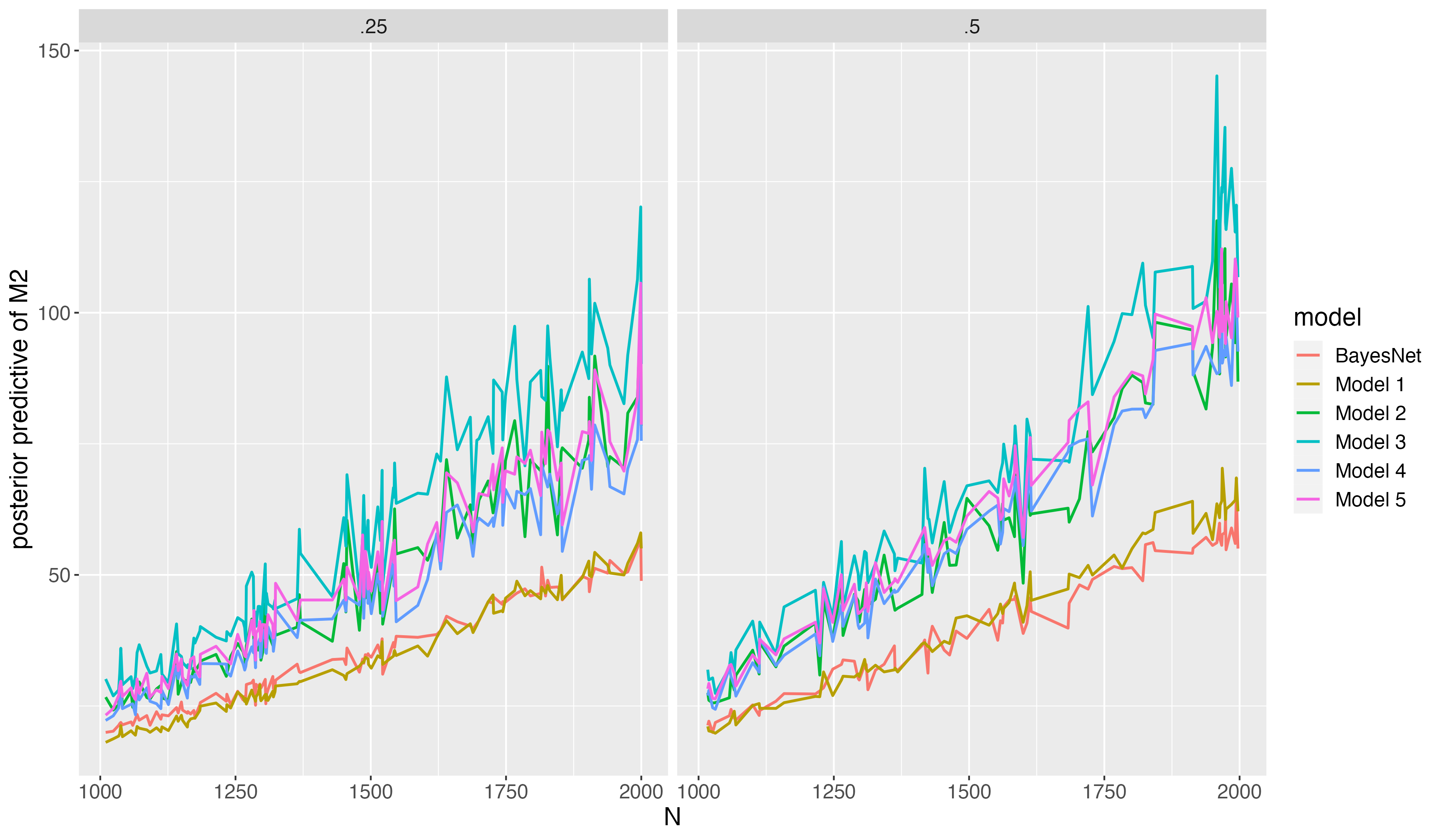
Title: Path Plot for Average Posterior Predictive M2
Findings
The correct model and the BayesNet model have lowest PP-M2 (best fit).
- When sample size is relatively small, the correct model slightly fit better than the BayesNet;
- When sample size is relatively large, the BayesNet fits better than the correct model
As sample size increases, the difference of PP-M2 among models gets larger. In other words, the PP-M2 has asymptotically more power detecting misfit.
The BayesNet model has least uncertainty of model predictive accuracy in term of variations of average PP-M2
As more items misspecify/underspecify attributes in Q-matrix, the PP-M2 gets higher.
Compare KS-PP-M2 to other methods
tab <- read.csv(glue::glue(root, "/Table/Table2_SummaryTableInfoCrit.csv"))
tab2 <- tab |>
mutate(WAIC = -2*WAIC) |>
group_by(Rho, Models) |>
summarise(
across(DIC:KS.PP.M2, list(mean = mean, sd = sd), .names = "{.col}_{.fn}")
) |>
ungroup() |>
mutate(
Model_group = case_when(
Models == "Model 1" ~ "Correct",
Models %in% c("Model 2", "Model 3") ~ "Underspecified",
Models %in% c("Model 4", "Model 5") ~ "Misspecified"
),
Models = factor(Models, levels = paste0("Model ", 1:5),
labels = c("Model 1", "Model 2:\n 10%", "Model 3:\n 20%",
"Model 4:\n 10%", "Model 5:\n 20%")),
)sumtab2 <- tab2 |>
mutate(Rho = factor(Rho, levels = c(25, 50),
labels = c("Skill Correlation is .25", "Skill Correlation is .50"))) |>
gt(rowname_col = "Model_group", groupname_col = "Rho") |>
cols_align(columns = Models,
align = "left") |>
fmt_number(contains("IC"), decimals = 0) |>
fmt_number(starts_with("KS.PP.M2"), decimals = 2) |>
cols_merge(
columns = starts_with("DIC"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("WAIC"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("AIC"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("BIC"),
pattern = "{1}({2})"
) |>
cols_merge(
columns = starts_with("KS.PP.M2"),
pattern = "{1}({2})"
) |>
tab_spanner(
label = "Information Criterion",
columns = contains("IC")
) |>
cols_label(
DIC_mean = "DIC",
WAIC_mean = "WAIC",
AIC_mean = "AIC",
BIC_mean = "BIC",
KS.PP.M2_mean = "KS-PP-M2"
) |>
cols_align(columns = ends_with("mean"),
align = "center") |>
tab_style(
style = cell_text(style = "italic"),
locations = cells_row_groups()
) |>
tab_style(
style = cell_text(weight = "bold"),
locations =
cells_body( # smaller value for correct model
columns = ends_with("mean"),
rows = c(1, 6)
)
) |>
data_color(
columns = c(contains("DIC_mean"), contains("AIC_mean")),
colors = scales::col_numeric(
palette = "RdPu",
domain = c(44000, 47000)
)
) |>
data_color(
columns = c(contains("BIC_mean")),
colors = scales::col_numeric(
palette = "RdPu",
domain = c(45000, 48000)
)
) |>
data_color(
columns = starts_with("KS.PP.M2"),
colors = scales::col_numeric(
palette = "BuGn",
domain = c(0, 1)
)
) |>
tab_footnote(
footnote =
md("**Bold**: The model with smallest average value of model selection indice."),
locations =
cells_column_spanners(spanners = "Information Criterion")
) |>
tab_footnote(
footnote =
html("<span style='color:red'>Information Criterion</span> & <span style='color:green'>KS-PP-M2</span>: lower values better model fit"),
locations =
cells_column_spanners(spanners = "Information Criterion")
) |>
as_raw_html()
sumtab2True Positive Rate:
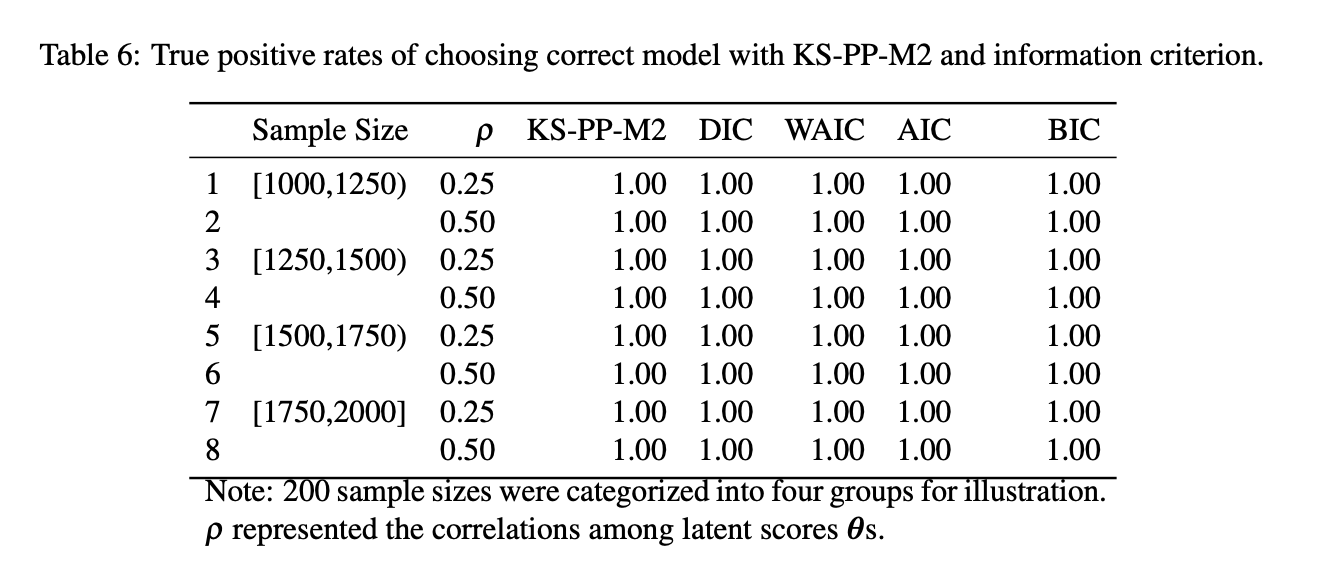
True Positive Rates of choosing correct model
Effects of Cognitive Diagnostic Index
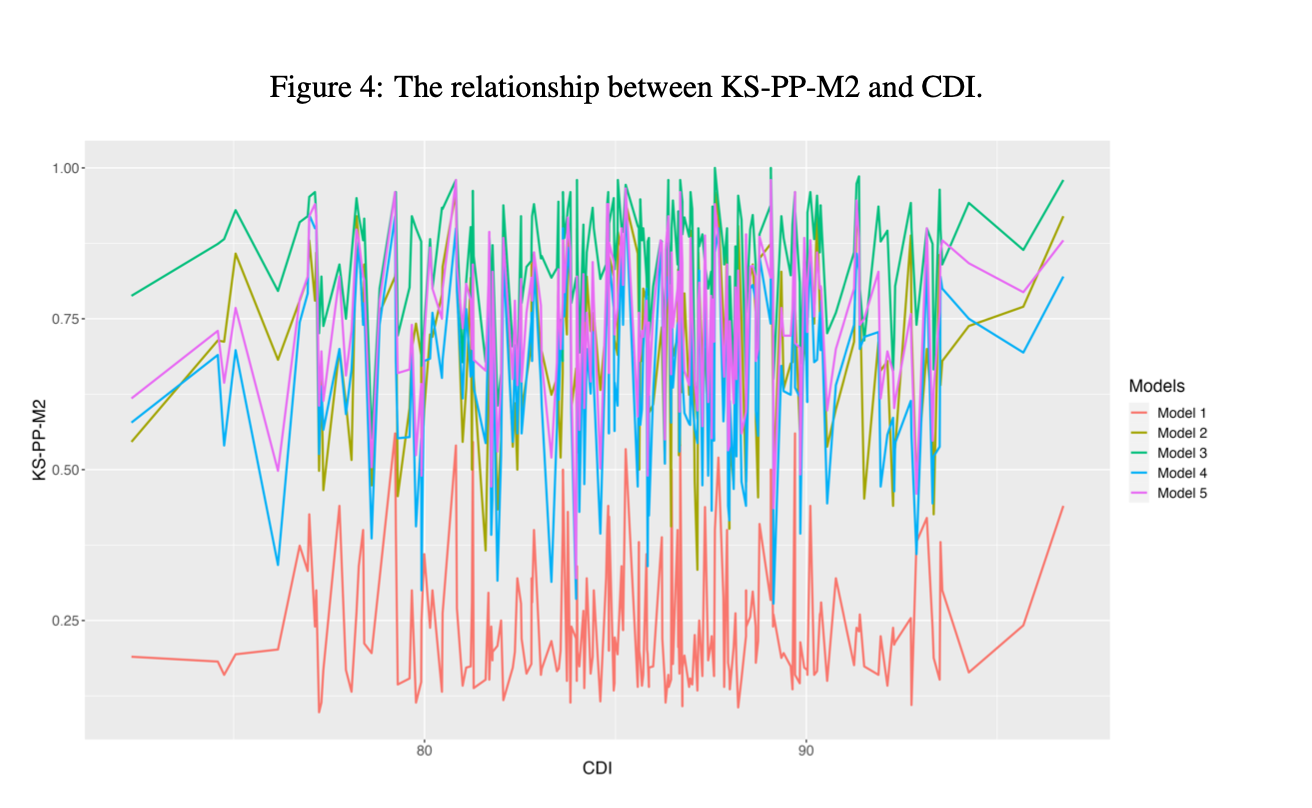
Effects of Cognitive Diagnostic Index (Cont.)
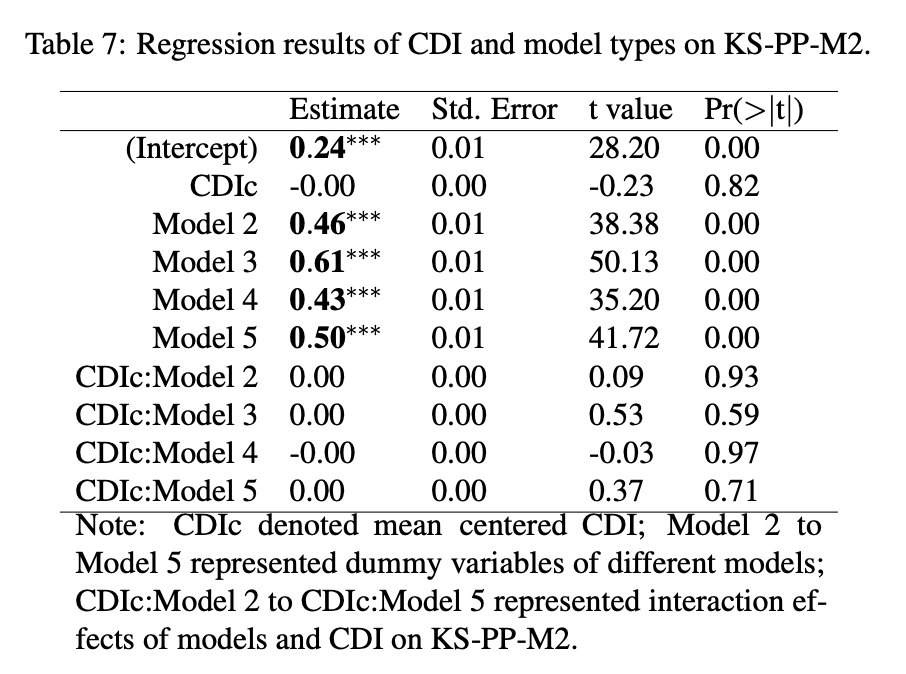
Conclusion (Simulation study)
Posterior predictive M2 statistics showed the Bayesian Network model and the correct model have best model fit.
Similar to information criteria, KS-PP-M2 can select data generation model from models with Q-matrix misspecification
Higher Q-matrix misspecification, KS-PP-M2 has higher values, which suggest worse model fit.
Compared to other methods, KS-PP-M2 has same power of selecting the better model and detecting Q-matrix misspecification under all conditions.
CDI (test-level discrimination power) has insignificant effect on the fit statistics of the proposed method.
Emprical Study
Research Questions
- How the proposed approach can be used for the model selection in real settings?
- Is the performance of the proposed approach comparable to other IC methods?
Design
The Examination for Certificate of Proficiency in English (ECPE) data was used as the example data.
One reference model and two analysis models: (1) three-dimensional model (the best fitted model in Templin & Hoffman, 2013); (2) two-dimensional model with randomly generated Q-matrix.
Measures: (1) absolute fit: PP-M2, (2) relative fit: KS-PP-M2, DIC and WAIC
Data and Settings
- ECPE data has 2,922 test takers and 28 items.
- Bayesian estimation were used with 2000 iterations and 1000 discarded burn-ins.
- Prior distribution setups are by default of blatent package
Result (Empirical study)
Density Plot of Posterior predictive M2
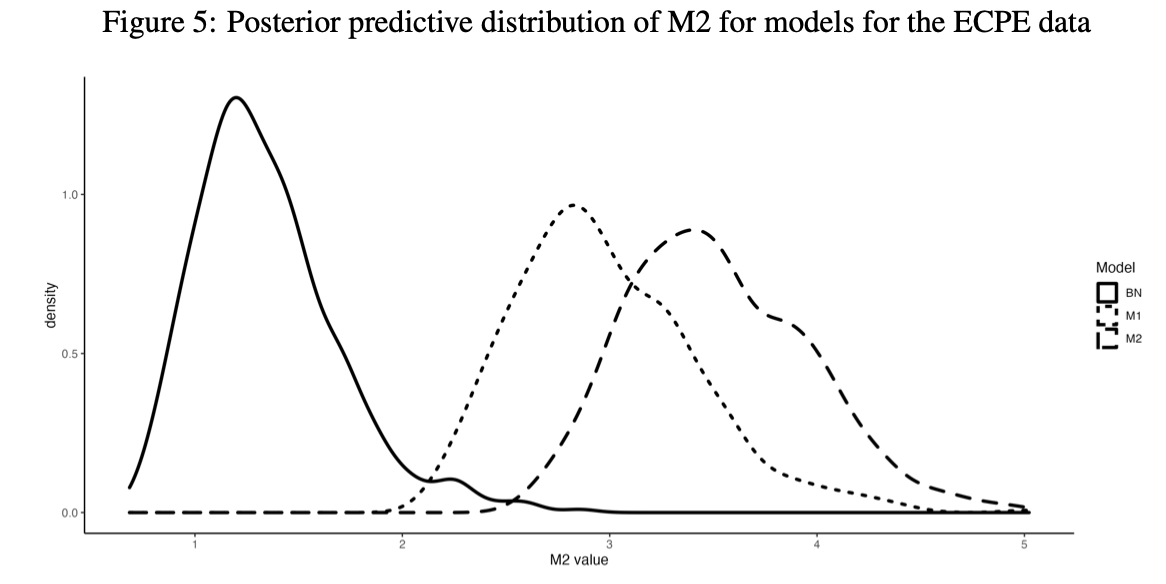
Note: solid line (the BayesNet model); dotted model (the three-dimension model); dashed line (the two-dimension model).
Model Selection Indices
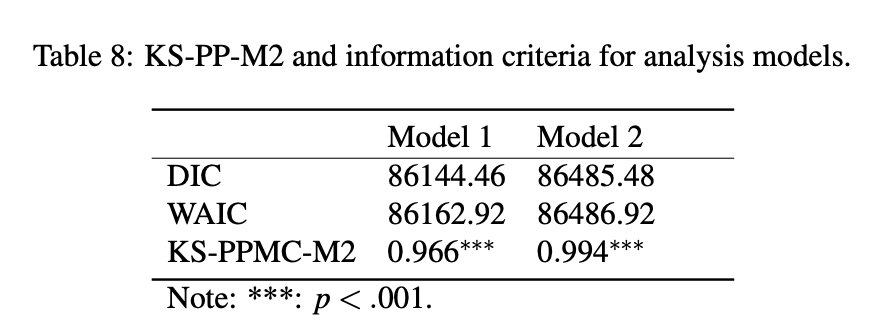
Note: Model 1 (three dimensional model); Model 2 (two dimensional model).
Findings (Emprical study)
According to the graphical checking of PP-M2, the BayesNet model is the best-fitting model, then followed by the three-dimensional model. The two-dimensioanl model has worst model fit.
DIC, WAIC, KS-PP-M2 all suggested that the three-dimensional model is better than the two-dimensional model.
KS-PP-M2 suggested that neither the three-dimensional model and the two-dimensional model have close model fit with BayesNet model.
Conclusion
- In both simulation and empirical study, posterior predictive M2 suggest BayesNet models and data generation model have close model fit statistics.
- KS statistics for posterior predictive M2 (KS-PP-M2) has same power detecting Q-matrix misspecification with other IC methods according TPR.
- Discrimination power of data has insignificant relationship with the proposed model checking indices
- KS-PP-M2 provides graphical checking for the variation of model fit indices.
Discussion
- When comparing multiple models, varied model selection methods are recommended to report.
- In Bayesian analysis, AIC/BIC are not fully Bayesian. They are not recommended in Bayesian framework. DIC has problems such as it may produce negative estimates of the effective number of parameters in a model and it is not defined for model with discrete parameters.
- WAIC is fully Bayesian and asymptotically equal to Bayesian cross-validation. LOO is also based on cross-validation approach.
- KS-PP-M2 approach is full Bayesian and provide uncertainty of the observed data.
- KS-PP-M2 could be a relative fit and posterior predictive M2 is a absolute fit.
- KS-PP-M2 is based on the BayesNet model
- KS-PP-M2 does not relied on likelihood function.
- KS-PP-M2 takes advatages of limited-information and potentially works for data with missing data.
Questions
Reference
Gelman, A., & Hill, J. (2006). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
Supplement: Information Criterion
DIC / WAIC
DIC is a somewhat Bayesian version of AIC that makes two changes, replacing the maximum likelihood estimate \(\theta\) with the posterior mean and replacing k with a data-based bias correction.1
WAIC is a more fully Bayesian approach for estimating the out-of-sample expectation, starting with the computed log pointwise posterior predictive density and then adding a correction for effective number of parameters to adjust for overfitting.
- DIC does not the whole posterior information and does not provide uncertainty of fit statistics.
- WAIC provides uncertainty (SE) and is popular but is not flexible to test certain aspects of data.
- Posterior predictive checking is flexible but not full Bayesian. It also has some theoretical issue.
Supplement II: Posterior predictive check
Simulating replicated data under the fitted model and then comparing these to the observed data (Gelman & Hill, 2006, p. 158)
Aims:
check local and global model-fit for some aspects of data they’re interested in
provide graphical evidence about model fit
Supplement III: “using the data twice”
One critique of posterior predictive check is it uses the data twice (Blei, 2011), which means data is not only used for estimating the model but also for checking if the model fits to the data.
- This is a bad idea, because it violates the likelihood principle.
- A typical way in statistics and machine learning literature:
Validate the model on external data
Supplement IV: Model Selection Problem exist when
multiple alternative models existed
uncertaity of dimensionality
Q-matrix misspecification
Supplement V: Factors of Model selection indices
Sample size
Discrimination information
Q-matrix
Model structure
Supplement VI: Fit Measures
Posterior Predictive M2
M2 is a limited-information statistics which calculated up-to second probabilities of item responses.
M2 more robust than full-information fit statistics in small sample sizes.
PP-M2 is M2 values conditional on posterior information. Lower average values suggest better model fit.
Cognitive diagnostic Index
Supplement VII: KS Statistics
library(tidyverse)
library(ggrepel)
set.seed(1234)
dat1 <- reactive({rnorm(1000, mean = input$mu1, sd = 1)})
dat2 <- reactive({rnorm(1000, mean = input$mu2, sd = 1)})
observeEvent(input$addModel, {
insertUI(
immediate = TRUE,
selector = "#addModel",
where = "afterEnd",
ui = sliderInput( inputId = "mu3", "Mean of alternative distribution:",
min = 0, max = 5, value = 4, step = 0.1 )
)
})
observe({
dat <- data.frame(dat1 = dat1(), dat2 = dat2()) |>
tidyr::pivot_longer(everything(),names_to = "dist", values_to = "value")
distText <- data.frame(
label = c("reference\nmodel", "target\nmodel"),
x = c(input$mu1, input$mu2),
y = c(0.2, 0.25)
)
output$distPlot <- renderPlot({
dat |>
ggplot() +
geom_density(aes(x = value, fill = dist), alpha = 0.6) +
geom_text(aes(x = x, y = y, label = label), data = distText, size = 5) +
scale_fill_manual(values = c("#E69F00", "#56B4E9"))
})
output$kstext <- renderUI({
txt <- capture.output(ks.test(dat1(), dat2()))
txt[4] <- "data: data1 and data2"
txt[5] <- paste0("Target Model:<b>", txt[5], "</b>")
HTML(paste0("<font size='3'>",txt, "</font>",collapse = "<br>"))
})
# add another model
observeEvent(input$mu3, {
set.seed(1234)
dat3 <- reactive({rnorm(1000, mean = input$mu3, sd = 1)})
dat <- data.frame(dat1 = dat1(), dat2 = dat2(), dat3 = dat3()) |>
tidyr::pivot_longer(everything(),names_to = "dist", values_to = "value")
distText <- data.frame(
label = c("reference\nmodel", "target\nmodel", "alternative\nmodel"),
x = c(input$mu1, input$mu2, input$mu3),
y = c(0.2, 0.25, 0.3)
)
output$distPlot <- renderPlot({
dat |>
ggplot() +
geom_density(aes(x = value, fill = dist), alpha = 0.6) +
geom_text(aes(x = x, y = y, label = label), data = distText, size = 5) +
scale_fill_manual(values = c("#E69F00", "#56B4E9", "firebrick"))
})
output$kstext <- renderUI({
txt <- capture.output(ks.test(dat1(), dat2()))
txt[4] <- "data: data1, data2 and data3"
txt[5] <- paste0("Target Model:<b>", txt[5], "</b>")
Model2 <- paste0("Alternative Model:<b>",capture.output(ks.test(dat1(), dat3()))[5], "</b>")
HTML(paste0("<font size='3'>", c(txt[1:5], Model2, txt[6:7]), "</font>", collapse = "<br>"))
})
})
})
Thesis Defence 2022