[1] 2.793716[1] -0.1416608Experimental Design in Education
2025-08-18
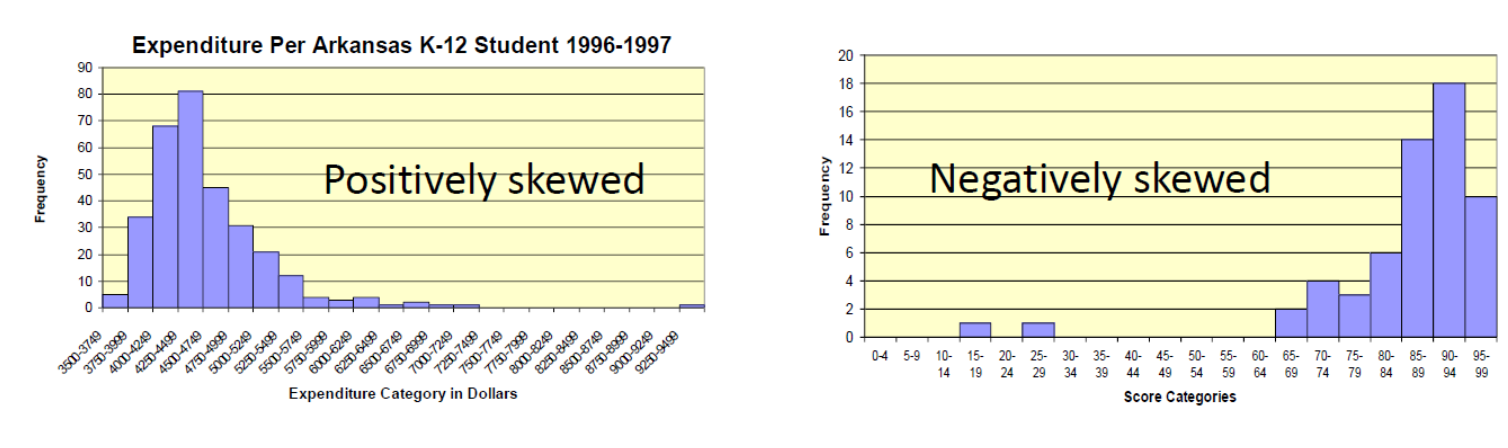
Examples of positive and negative skewness in distributions


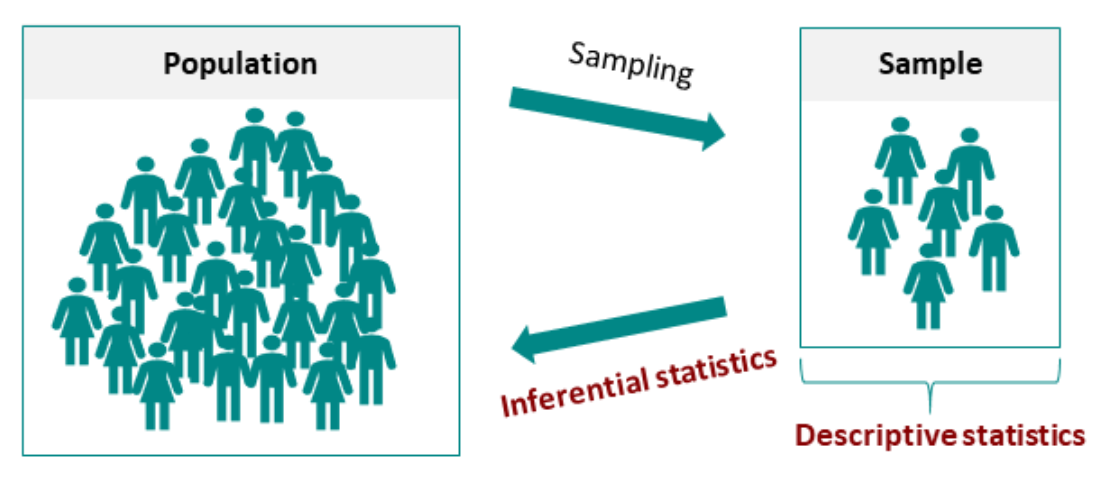
The relationship between population, sample, and inference
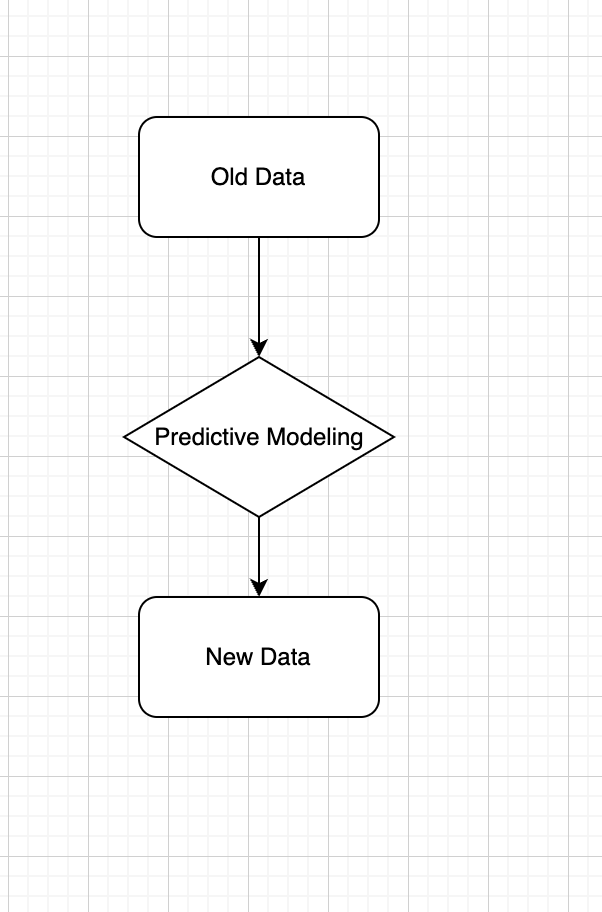
Definition: Use observed data to produce the most accurate prediction possible for new data. Here, the primary goal is that the predicted values have the highest possible fidelity to the true value of the new data.
Example: A simple example would be for a book buyer to predict how many copies of a particular book should be shipped to their store for the next month.
Example of predictive statistics workflow
How many houses burned in California wildfire in the first week?
Which factor is most important causing the fires?
How likely the California wildfire will not happen again in next 5 years?
How likely human will live on Mars?
Which type of statistics is used by ChatGPT?
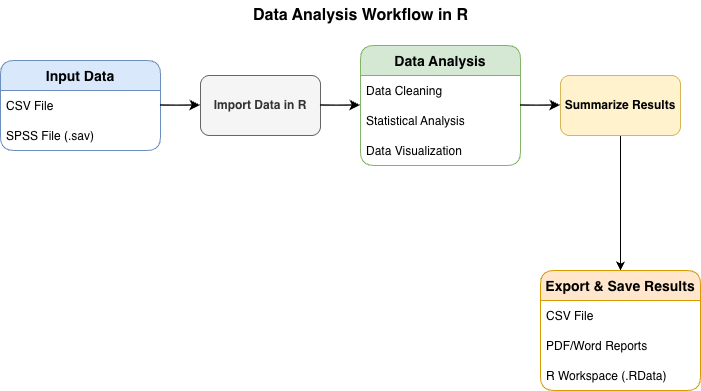
Data Analysis Workflow in R
remotes::install_github("JihongZ/ESRM64103")
library(ESRM64103)
library(dplyr)
exp_political_attitude
exp_political_attitude$party <- factor(exp_political_attitude$party,
levels = c("Democrat", "Republican", "Independent"))
mean_byGroup <- exp_political_attitude |>
group_by(party) |>
summarise(Mean = mean(scores),
SD = round(sd(scores), 2),
Vars = round(var(scores), 2),
N = n())
mean_byGroup
anova_model <- lm(scores ~ party, data = exp_political_attitude)
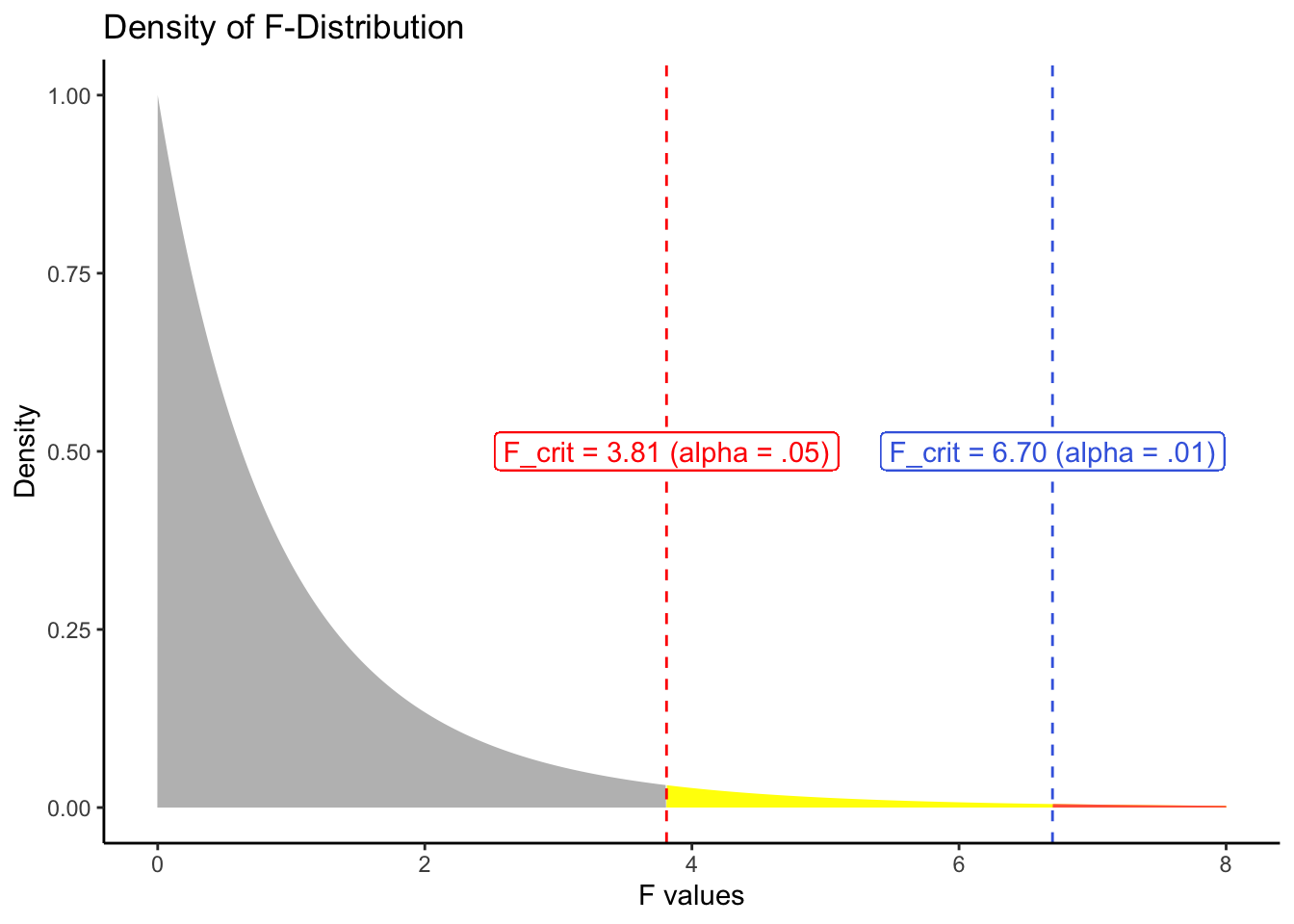
anova(anova_model)F-statistic has two degree of freedoms (df = 2). This is the density distribution of F-statistics for degree of freedoms as 2 and 13.
# Set degrees of freedom for the numerator and denominator
num_df <- 2 # Change this as per your specification
den_df <- 13 # Change this as per your specification
# Generate a sequence of F values
f_values <- seq(0, 8, length.out = 1000)
# Calculate the density of the F-distribution
f_density <- df(f_values, df1 = num_df, df2 = den_df)
# Create a data frame for plotting
data_to_plot <- data.frame(F_Values = f_values, Density = f_density)
data_to_plot$Reject05 <- data_to_plot$F_Values > 3.81
data_to_plot$Reject01 <- data_to_plot$F_Values > 6.70
# Plot the density using ggplot2
ggplot(data_to_plot) +
geom_area(aes(x = F_Values, y = Density), fill = "grey",
data = filter(data_to_plot, !Reject05)) + # Draw the line
geom_area(aes(x = F_Values, y = Density), fill = "yellow",
data = filter(data_to_plot, Reject05)) + # Draw the line
geom_area(aes(x = F_Values, y = Density), fill = "tomato",
data = filter(data_to_plot, Reject01)) + # Draw the line
geom_vline(xintercept = 3.81, linetype = "dashed", color = "red") +
geom_label(label = "F_crit = 3.81 (alpha = .05)", x = 3.81, y = .5, color = "red") +
geom_vline(xintercept = 6.70, linetype = "dashed", color = "royalblue") +
geom_label(label = "F_crit = 6.70 (alpha = .01)", x = 6.70, y = .5, color = "royalblue") +
ggtitle("Density of F-Distribution") +
xlab("F values") +
ylab("Density") +
theme_classic()Investigate where the variability in the outcome comes from.
In this study: Do people’s attitude scores differ because of their political party affiliation?
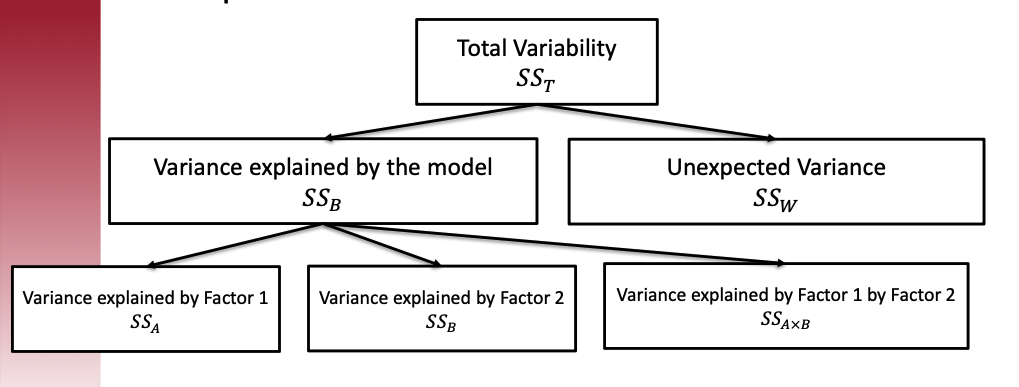
When we have factors influencing the outcome, the total variability can be decomposed as follows:
Sources of variability: Total variance can be decomposed into between-group and within-group variance
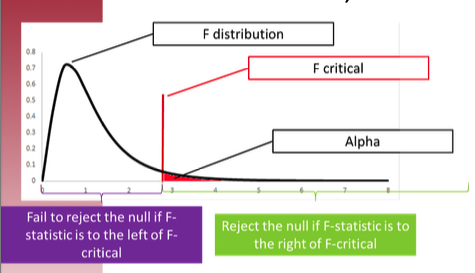
F-distribution showing rejection regions for different alpha levels