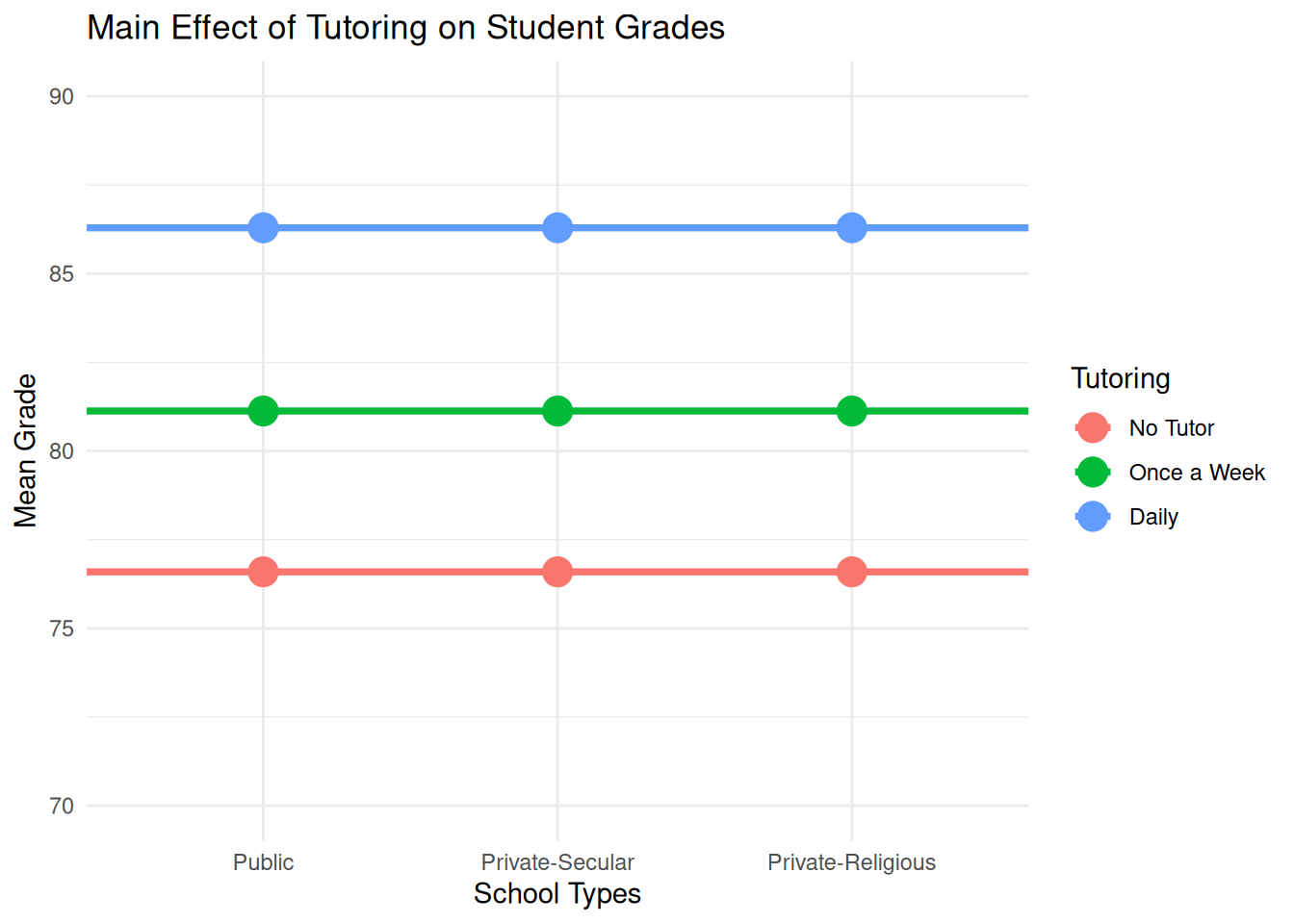
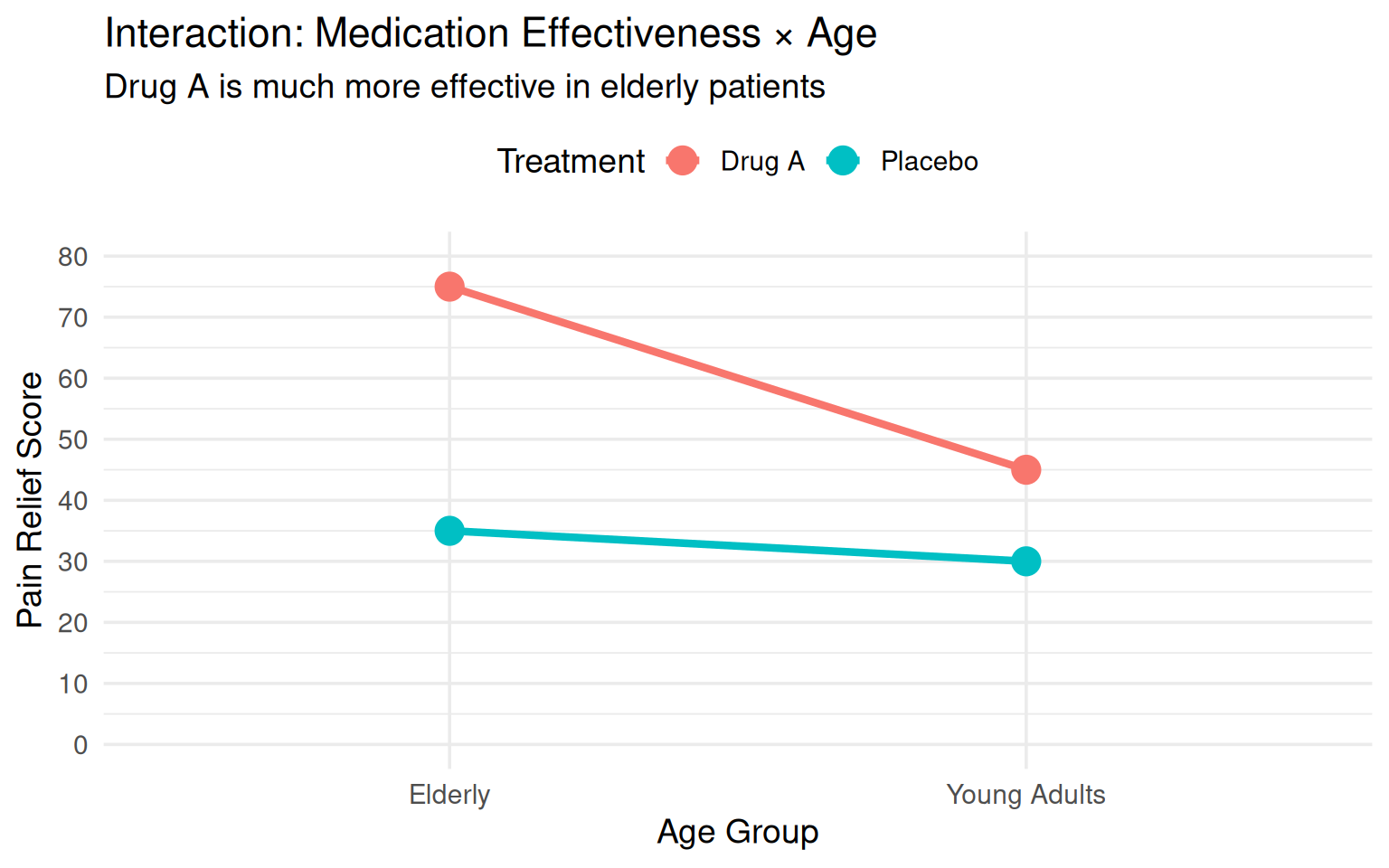
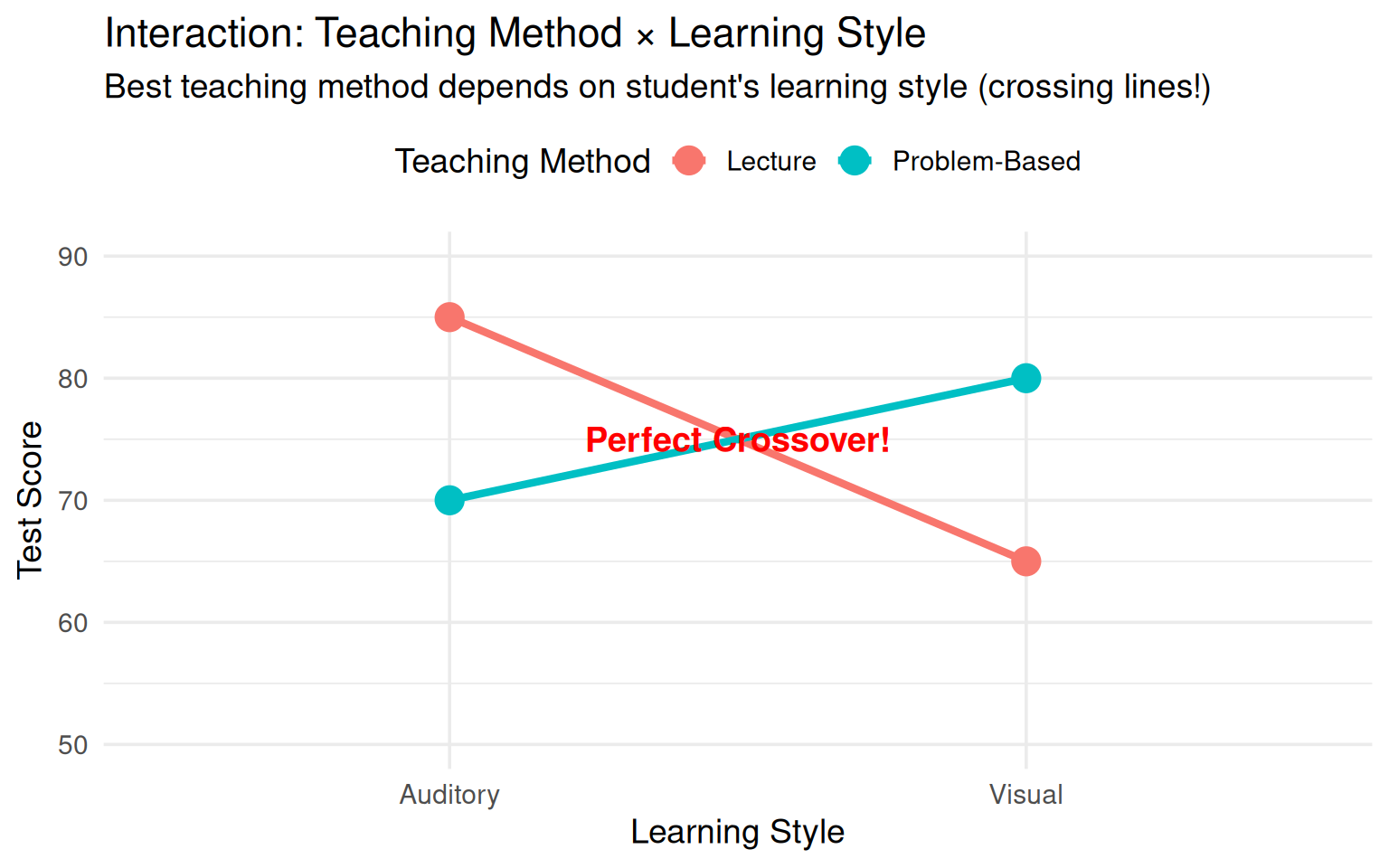
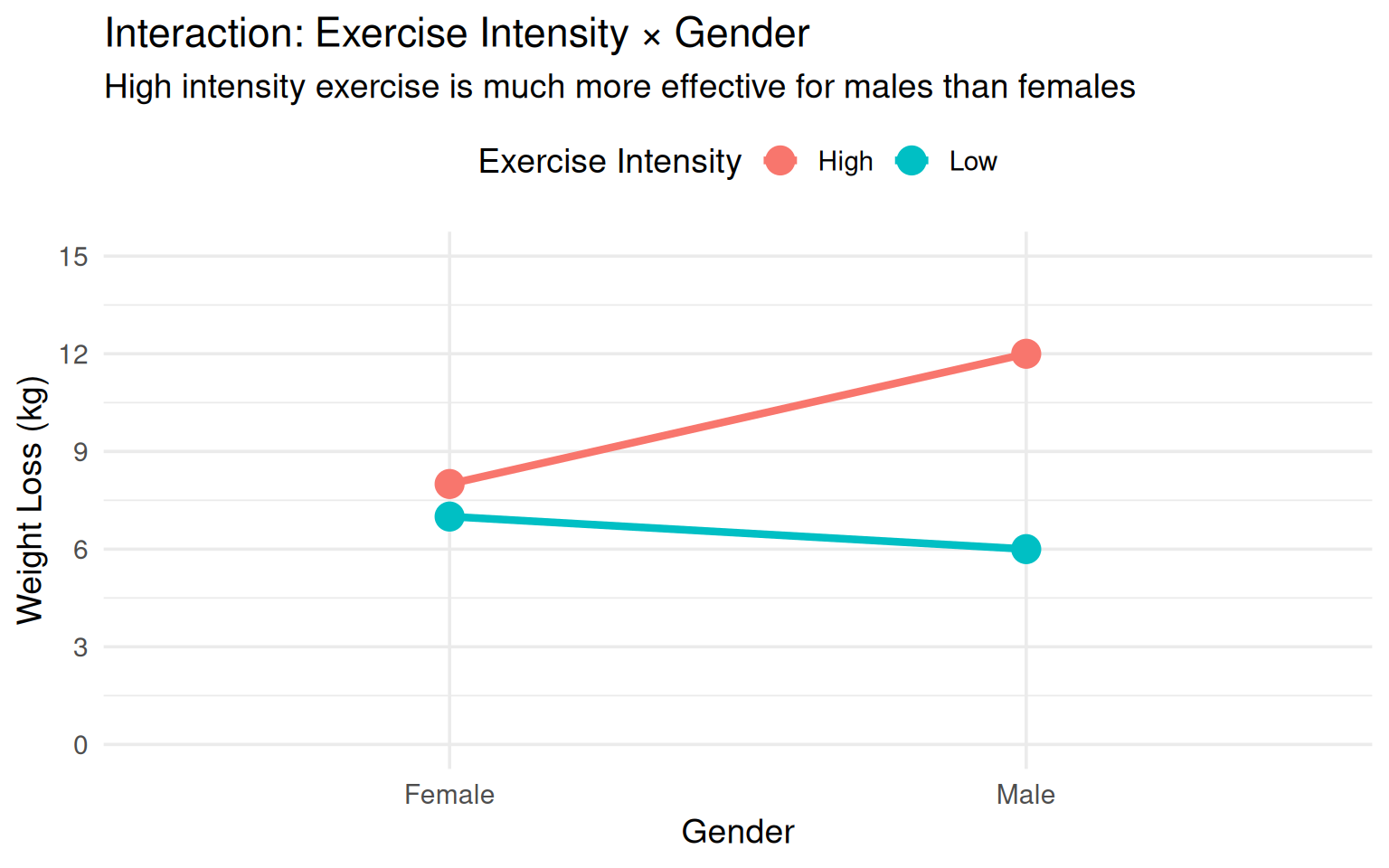
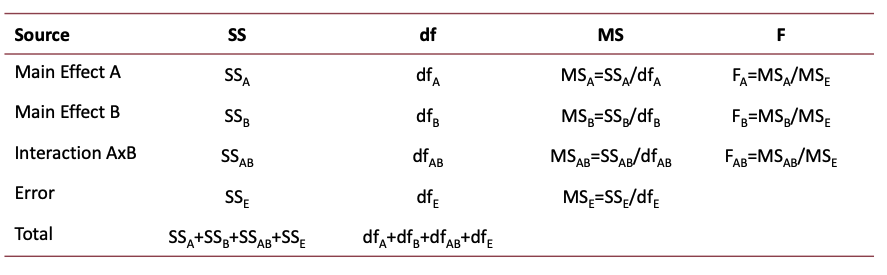
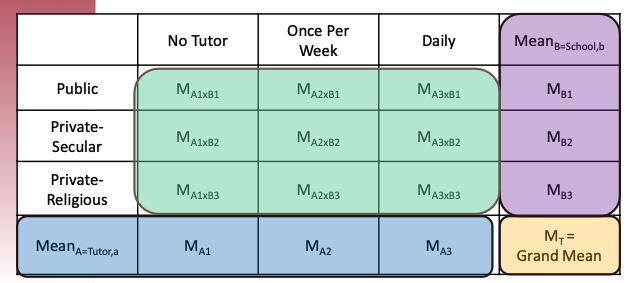
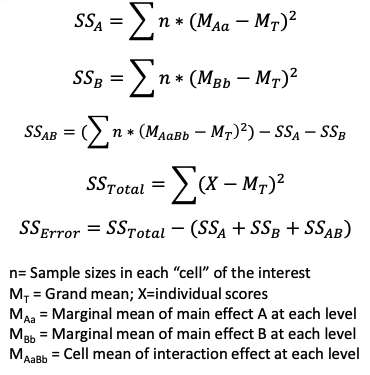
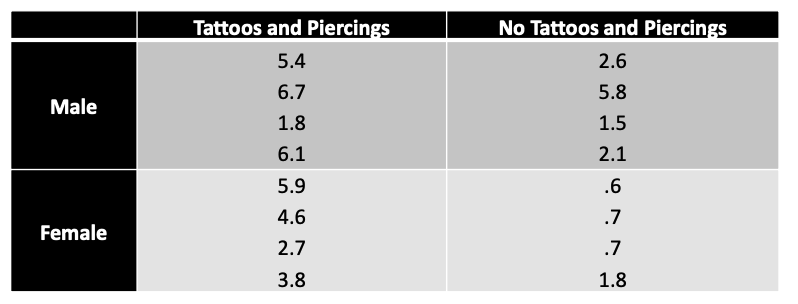
library(tidyverse)
# Set seed for reproducibility
set.seed(123)
# Define sample size per group
n <- 30
# Define factor levels
tutoring <- rep(c("No Tutor", "Once a Week", "Daily"), each = 3 * n)
school <- rep(c("Public", "Private-Secular", "Private-Religious"), times = n * 3)
# Simulate student grades with assumed effects
grades <- c(
rnorm(n, mean = 75, sd = 5), # No tutor, Public
rnorm(n, mean = 78, sd = 5), # No tutor, Private-Secular
rnorm(n, mean = 76, sd = 5), # No tutor, Private-Religious
rnorm(n, mean = 80, sd = 5), # Once a week, Public
rnorm(n, mean = 83, sd = 5), # Once a week, Private-Secular
rnorm(n, mean = 81, sd = 5), # Once a week, Private-Religious
rnorm(n, mean = 85, sd = 5), # Daily, Public
rnorm(n, mean = 88, sd = 5), # Daily, Private-Secular
rnorm(n, mean = 86, sd = 5) # Daily, Private-Religious
)
# Create a dataframe
data <- data.frame(
Tutoring = factor(tutoring, levels = c("No Tutor", "Once a Week", "Daily")),
School = factor(school, levels = c("Public", "Private-Secular", "Private-Religious")),
Grades = grades
)