Rows: 500
Columns: 17
$ Age_baseline <int> 15, 15, 16, 15, 15, 16, 16, 15, 15, 15, 15, 16, 16,…
$ Sex <chr> "boys", "girls", "boys", "boys", "boys", "boys", "b…
$ Ethnicity_baseline <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ Origin_baseline <int> 2, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 1, 2, 1, 2, 2, 1, …
$ BMI_avg <dbl> 15.58863, 25.35745, 34.67057, 30.76086, 26.52223, 2…
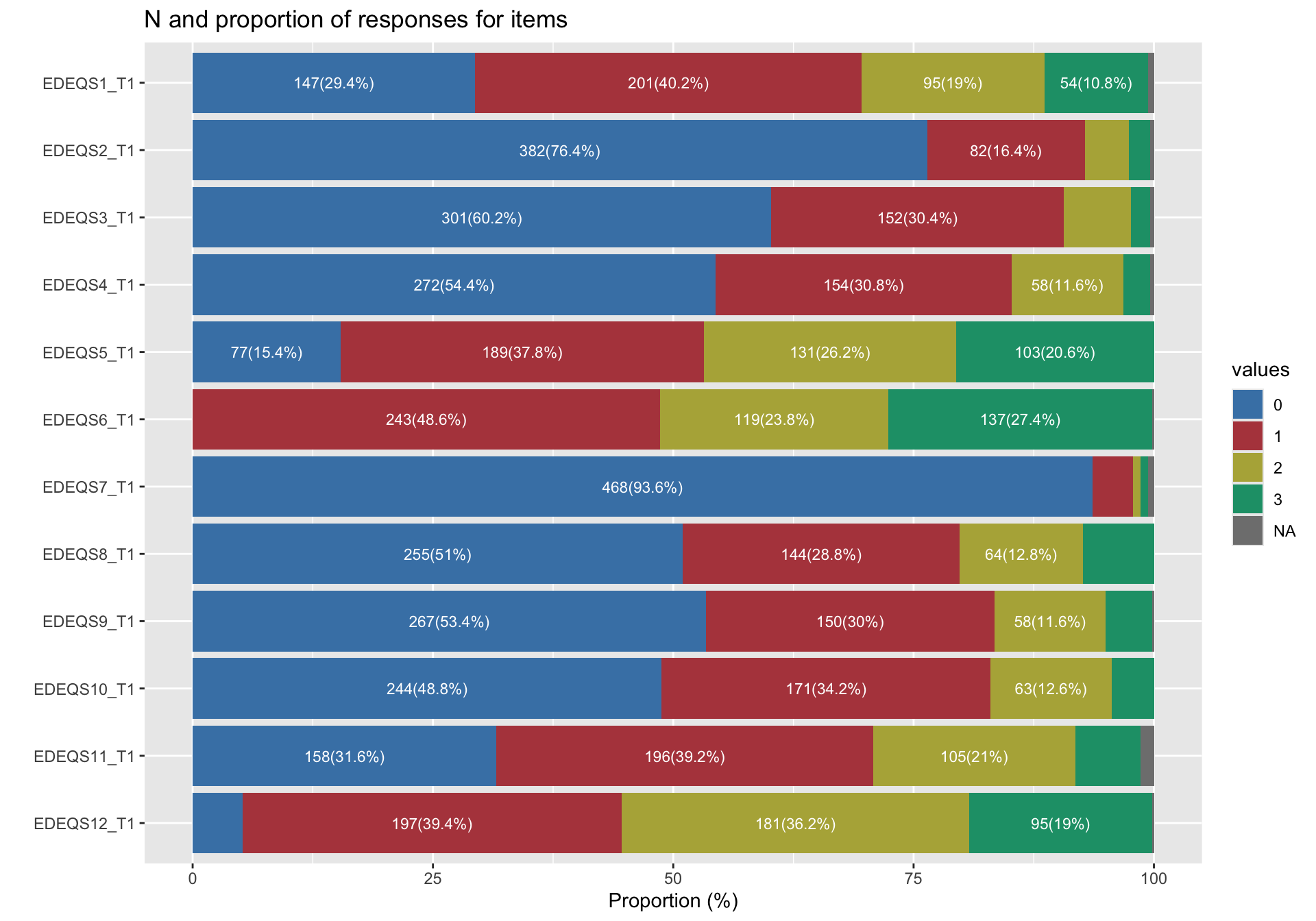
$ EDEQS1_T1 <int> 0, 3, 2, 2, 0, 1, 0, 2, 1, 3, 1, 1, 0, 0, 3, 2, 3, …
$ EDEQS2_T1 <int> 0, 0, 1, 0, 0, 1, 0, 0, 0, 3, 1, 0, 0, 0, 0, 1, 1, …
$ EDEQS3_T1 <int> 1, 1, 2, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, …
$ EDEQS4_T1 <int> 2, 0, 2, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 2, 0, …
$ EDEQS5_T1 <int> 3, 3, 0, 3, 0, 1, 0, 3, 3, 3, 3, 2, 0, 2, 2, 3, 3, …
$ EDEQS6_T1 <int> NA, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,…
$ EDEQS7_T1 <int> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ EDEQS8_T1 <int> 1, 2, 2, 1, 1, 2, 0, 0, 0, 0, 0, 2, 0, 3, 3, 2, 0, …
$ EDEQS9_T1 <int> 1, 0, 3, 3, 1, 0, 0, 0, 1, 2, 2, 1, 0, 0, 1, 1, 1, …
$ EDEQS10_T1 <int> 2, 0, 1, 2, 1, 0, 2, 0, 1, 3, 2, 0, 0, 0, 1, 2, 1, …
$ EDEQS11_T1 <int> 0, 2, 3, 0, 2, 1, 1, NA, 1, 1, 1, 0, 3, 0, 2, 2, 1,…
$ EDEQS12_T1 <int> 0, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 1, 3, 3, 2, 3, 3, …