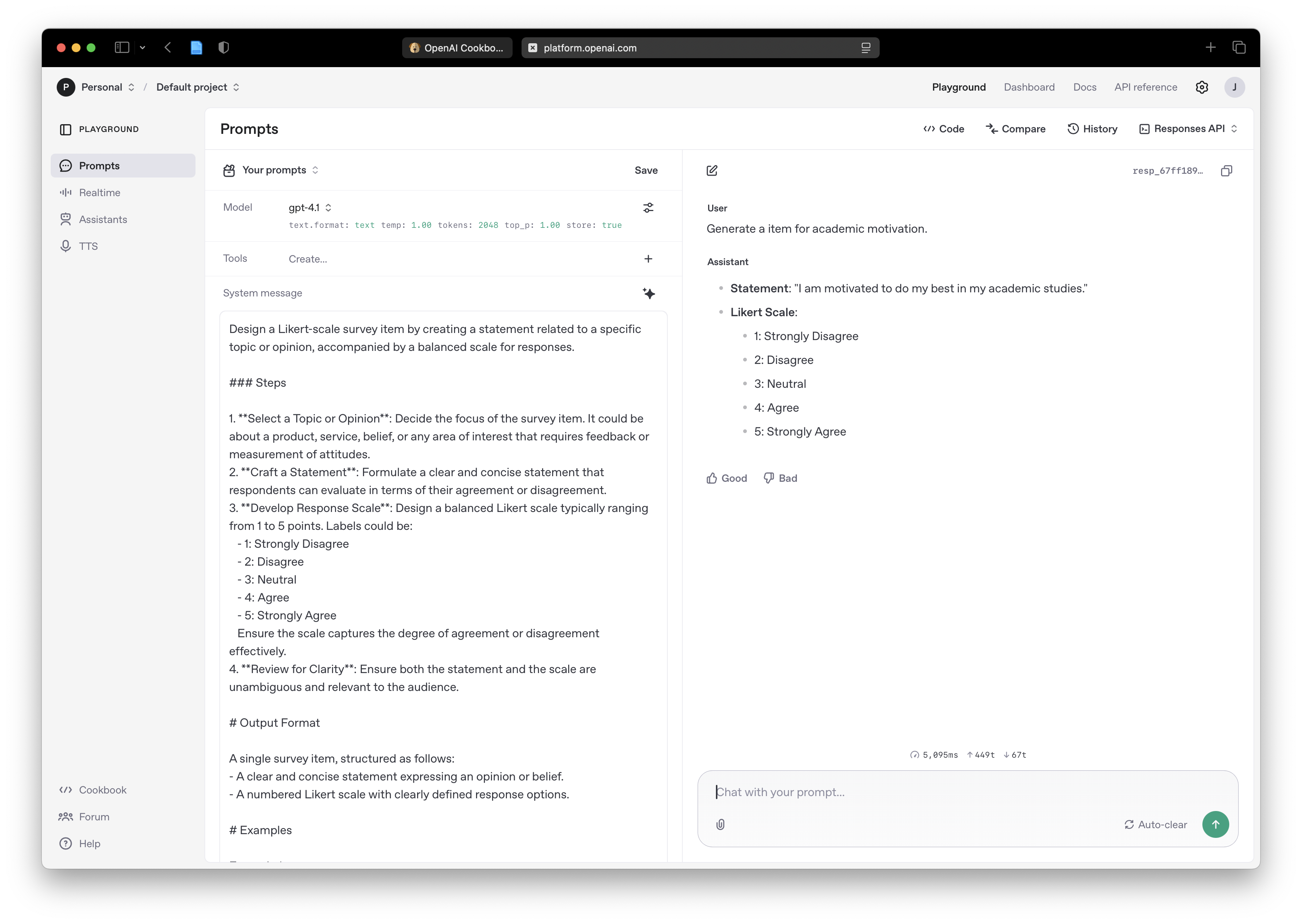
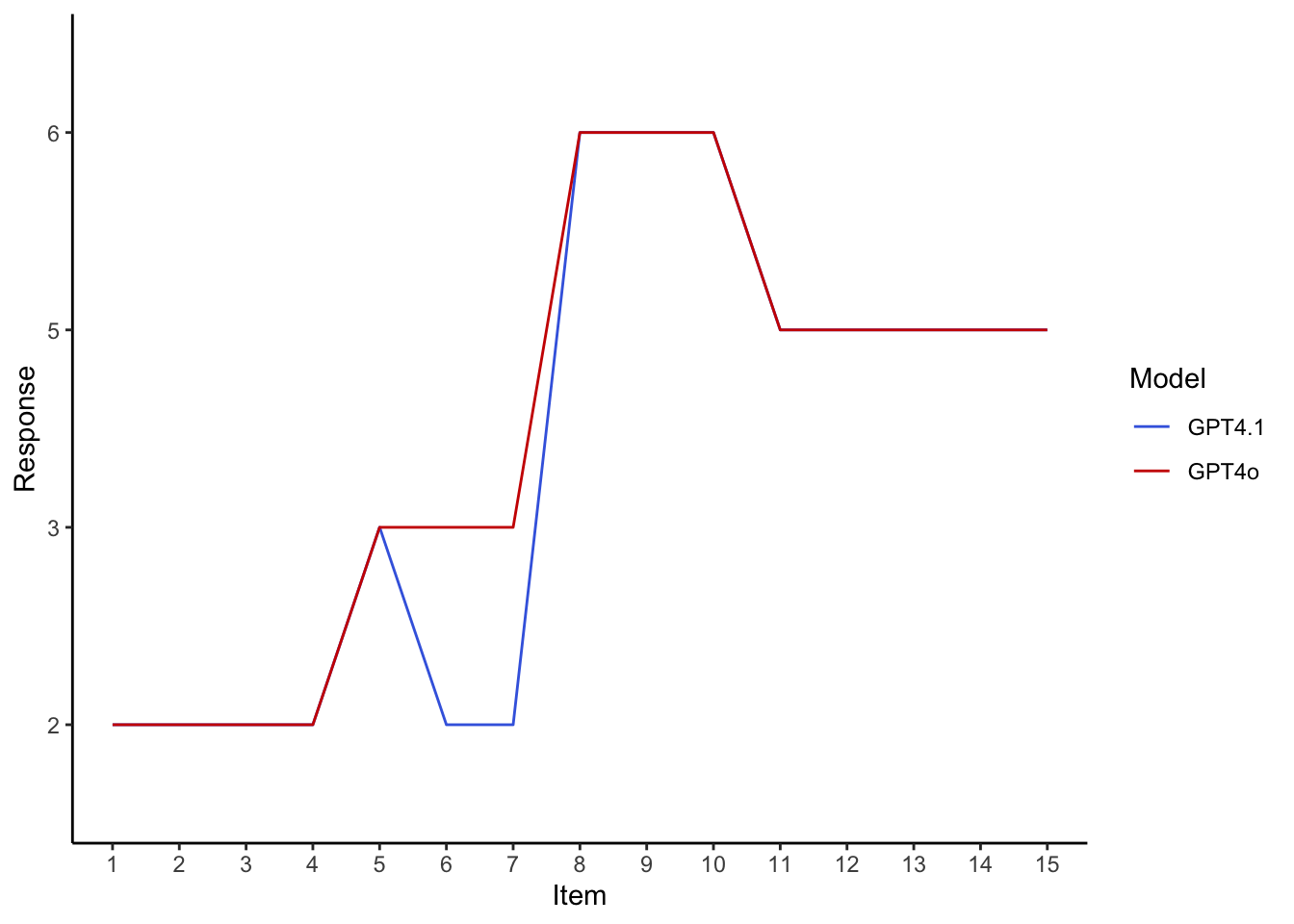
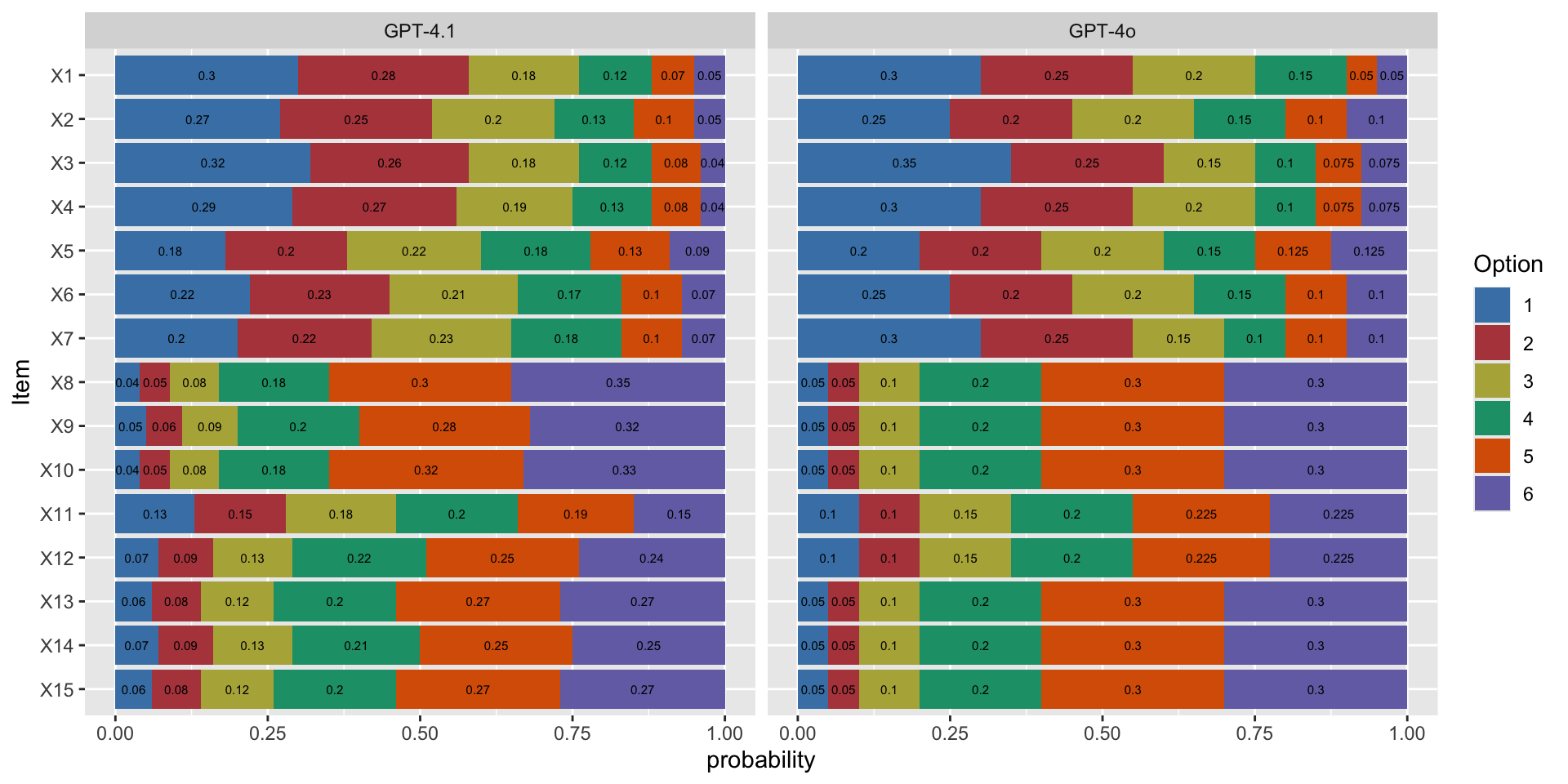
X1_k1:0.300,X1_k2:0.250,X1_k3:0.200,X1_k4:0.150,X1_k5:0.050,X1_k6:0.050;
X2_k1:0.250,X2_k2:0.200,X2_k3:0.200,X2_k4:0.150,X2_k5:0.100,X2_k6:0.100;
X3_k1:0.350,X3_k2:0.250,X3_k3:0.150,X3_k4:0.100,X3_k5:0.075,X3_k6:0.075;
X4_k1:0.300,X4_k2:0.250,X4_k3:0.200,X4_k4:0.100,X4_k5:0.075,X4_k6:0.075;
X5_k1:0.200,X5_k2:0.200,X5_k3:0.200,X5_k4:0.150,X5_k5:0.125,X5_k6:0.125;
X6_k1:0.250,X6_k2:0.200,X6_k3:0.200,X6_k4:0.150,X6_k5:0.100,X6_k6:0.100;
X7_k1:0.300,X7_k2:0.250,X7_k3:0.150,X7_k4:0.100,X7_k5:0.100,X7_k6:0.100;
X8_k1:0.050,X8_k2:0.050,X8_k3:0.100,X8_k4:0.200,X8_k5:0.300,X8_k6:0.300;
X9_k1:0.050,X9_k2:0.050,X9_k3:0.100,X9_k4:0.200,X9_k5:0.300,X9_k6:0.300;
X10_k1:0.050,X10_k2:0.050,X10_k3:0.100,X10_k4:0.200,X10_k5:0.300,X10_k6:0.300;
X11_k1:0.100,X11_k2:0.100,X11_k3:0.150,X11_k4:0.200,X11_k5:0.225,X11_k6:0.225;
X12_k1:0.100,X12_k2:0.100,X12_k3:0.150,X12_k4:0.200,X12_k5:0.225,X12_k6:0.225;
X13_k1:0.050,X13_k2:0.050,X13_k3:0.100,X13_k4:0.200,X13_k5:0.300,X13_k6:0.300;
X14_k1:0.050,X14_k2:0.050,X14_k3:0.100,X14_k4:0.200,X14_k5:0.300,X14_k6:0.300;
X15_k1:0.050,X15_k2:0.050,X15_k3:0.100,X15_k4:0.200,X15_k5:0.300,X15_k6:0.300;