A friend of mine recently asked me a question about network community: in her recent research, a network without a defined community yields different estimates from one with a community defined. Why does this happen? In this blog, I try to dive a little deeper into community issues in psychometric network analysis. You can find my previous post on the estimation methods of network analysis - How To Choose Network Analysis Estimation For Application Research.
This blog instead aims to talk about various aspects of community detection in psychometric network analysis, including the following questions:
What is “node community”?
Why we need communities of nodes in network analysis?
How communities are generated in the network using qgraph?
How to identify those communities given a network?
Click this to see R code
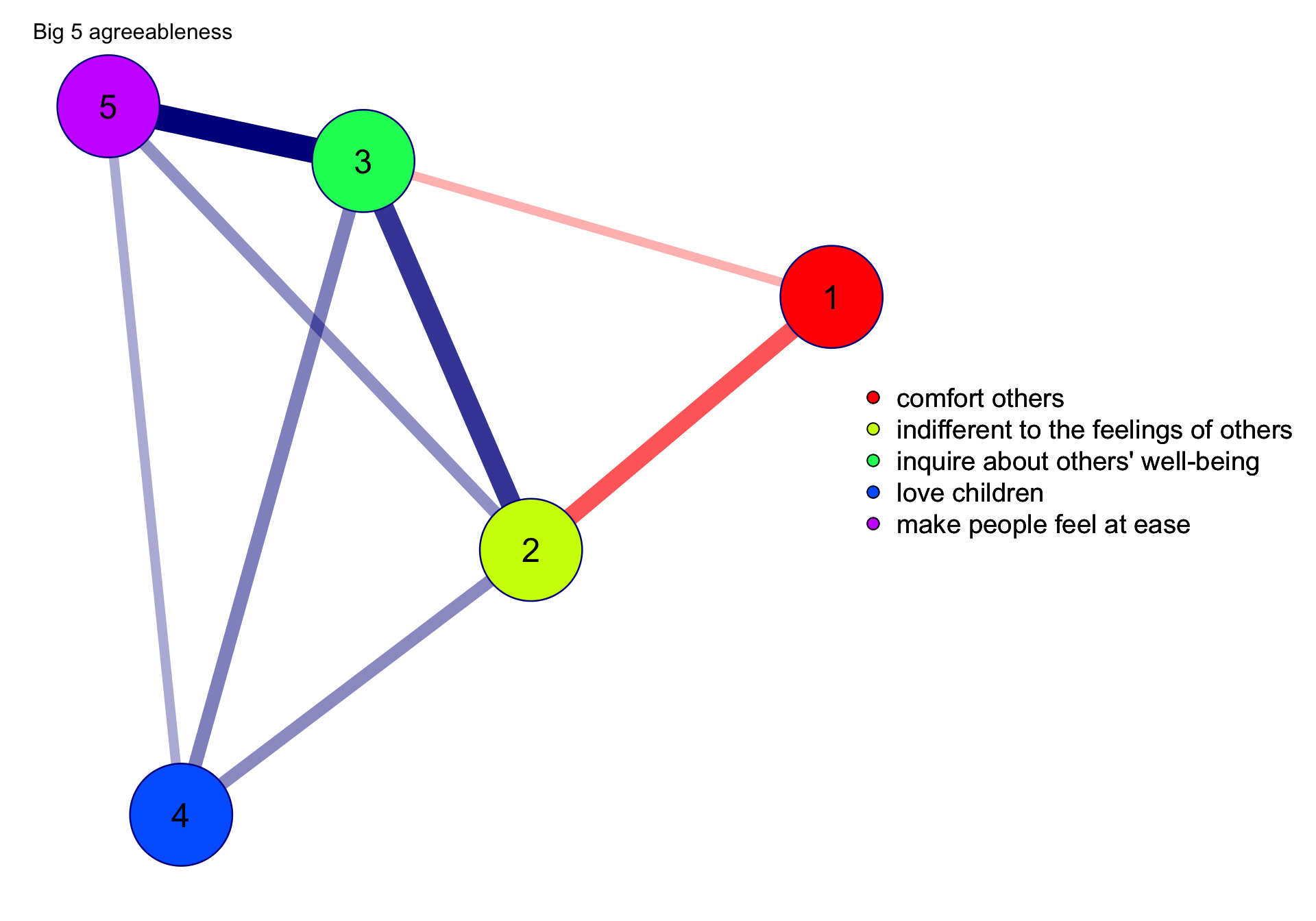
library(psychonetrics)# Load bfi data from psych package:library(psychTools)# Also load dplyr for the pipe operator:library(dplyr)data(bfi)# Let's take the agreeableness items, and gender:ConsData <- bfi |>select(A1:A5, gender) |>na.omit() # Let's remove missingness (otherwise use Estimator = "FIML)# Define variables:vars <-names(ConsData)[1:5]# Saturated estimation:mod_saturated <-ggm(ConsData, vars = vars)# Run the model:mod_saturated <- mod_saturated |>runmodel()# Labels:labels <-c("indifferent to the feelings of others","inquire about others' well-being","comfort others","love children","make people feel at ease")# We can also fit an empty network:mod0 <-ggm(ConsData, vars = vars, omega ="zero")# Run the model:mod0 <- mod0 |>runmodel()# To automatically add along modification indices, we can use stepup:mod1 <- mod0 |>stepup()# Let's also prune all non-significant edges to finish:mod1 <- mod1 |>prune()qgraph::qgraph(getmatrix(mod1, "omega"),layout="spring",groups = labels,title ="Big 5 agreeableness",theme ="Borkulo",bg =rgb(red =145, green =203, blue =215, alpha = .2196078431, maxColorValue =255),transparency =TRUE)
1 Big problem in the network analysis
As noted in Eiko’s post (E. Fried, 2016) – authors sometimes over-interpret the network visualization of their data, concluding that some meaningful modules exist. This over-interpretation may lead to Type I error (mistakenly clustering nodes with weak connections into a community) or Type II error (failing to cluster nodes with strong connections into a community). In other words, researchers have found that relying on visual inspection of network structure cannot yield reliable conclusions about which nodes should be clustered together and which ones should not, especially in complex network structures (e.g., > 20 nodes).
The identification of node clusters is not a new topic; it is typically called “Community Detection” in graph theory (Fortunato, 2010). This problem arises from a phenomenon called “Community Structure” (Girvan & Newman, 2002) or “Clustering”, which has been found in various types of networks. This community structure has two characteristics:
Heterogeneity of node degree: nodes with high degree (more neighbors/ high betweenness) coexist with nodes with low degree.
Heterogeneity of edge strength: high concentrations of edges within certain “groups” of nodes, even though those “groups” are visually inspected.
Given this community structure, Community (or called clusters or modules) is defined as groups of nodes which probably share common properties and / or play similar roles within the graph(Fortunato, 2010). This is actually a very broad definition which does not answer what are “common properties” and “similar roles” in a network graph. The reason for this vagueness is the variety of networks across different domains.
For example, within a social network of one person, one individual is considered as a node and his/her social relationships with other people as edges, then “communities” may be conceptualized as family, company, or any other social groups. The latent common causes of community in a social network may be the shared emotional patterns constructed via family education, close levels of cognitive abilities within the same university/college/classroom, or similar behavioral patterns under company policy. In protein-protein interaction networks, communities are likely to group proteins having the same specific function within the cell. In the graph of the World Wide Web, community may correspond to groups of web pages dealing with the same or related topics. The regression-based relationship between community and external factors has not been well developed to my knowledge, i.e., the relationship between depression community with age, education, and other disorders. Currently, community-level centrality-based network scores (Zhang & Liang, 2024) can be used as measurement of the community, which then can potentially be used as independent variables or outcome in a regression model. However, network scores are suffering from interpretability in psychometrics and relevant research on this topic is still sparse. Similar idea can be found in other psychometric modeling, such as latent regression model in latent variable modeling literature (Andersson & Xin, 2021; Yamaguchi & Zhang, 2023) or the structural model in structural equation modeling.
Back to the community conceptualization in psychological area, especially psychiatry, the community is usually associated with syndromes or comorbidity. According to Wikipedia, a syndrome is a set of medical signs and symptoms which are correlated with each other and often associated with a particular disease or disorder. Some psychological syndromes may present comorbidity of symptoms, which refers to simultaneous presence of two or more psychological symptoms in a same individual within a time frame (co-occurring, concurrent). In an earlier paper, Borsboom (2002) took the DSM-IV (Diagnostic and Statistical Manual of Mental Disorders) as an example and argued that “… Comorbidity appears to be, at least partially and in particular for mood, anxiety, and substance abuse disorders, encoded in the structure of the diagnostic criteria themselves” (Borsboom, 2002), but he did not link the “comorbidity” of a cluster of highly connected symptoms to the statistical concept of “community” in a network graph. It was not until the paper of Cramer et al. (2010) that the symptom community as a local connectivity was considered as syndromes, while symptoms clusters are interconnected by individual symptoms (“bridge symptoms”) that form the boundaries between the various basic syndromes of psychiatric disorders (Goekoop & Goekoop, 2014). Goekoop & Goekoop (2014) also emphasized that the presence of bridge symptoms that connects symptom clusters (communities / syndromes) plays a key role that can be identified as potential targets for treatment.
2 Identify Community
There are two ways of defining communities in psychometric networks: the exploratory method and the confirmatory method. The exploratory method has deep roots in graph theory (e.g., exploratory graphical analysis). Exploratory graphical analysis (EGA) makes use of community detection algorithm to detect potential communities in a complex network structure.
In psychometric literature, however, confirmatory network analysis has become more and more popular (Du et al., 2024). Although the value of exploratory research remains indisputable, the field of psychology is facing an increasing demand for theory- and hypothesis-testing research, which serves to confirm, refute, or refine existing theories (Du et al., 2024; E. I. Fried, 2020). For example, many “communities” should correspond to theoretical constructs in psychology or education settings. That is, psychopathology syndromes mentioned above must have a precise definition in DSM-V for clinician reference, so the relevant indicators (nodes) should then be grouped into one community prior to the network analysis. The network modeling with pre-defined communities is called confirmatory network analysis. As noted by Hevey (2018), “… much of the research in psychological networks has been based on exploratory data analyses to generate networks; there is a need to progress towards confirmatory network modelling wherein hypotheses about network structure are formally tested.”
E. I. Fried (2020) mentioned some challenges in psychology research and argued that the core issues—latent theories, weak theories, and conflating theoretical and statistical models—are common and harmful, facilitate invalid inferences, and stand in the way of theory failure and reform.
The statistical and theoretical models are conflated without concrete evidence of the existence of psychological constructs.
Unclear theoretical grounds, and ambiguity about what the theory actually explains or predicts.
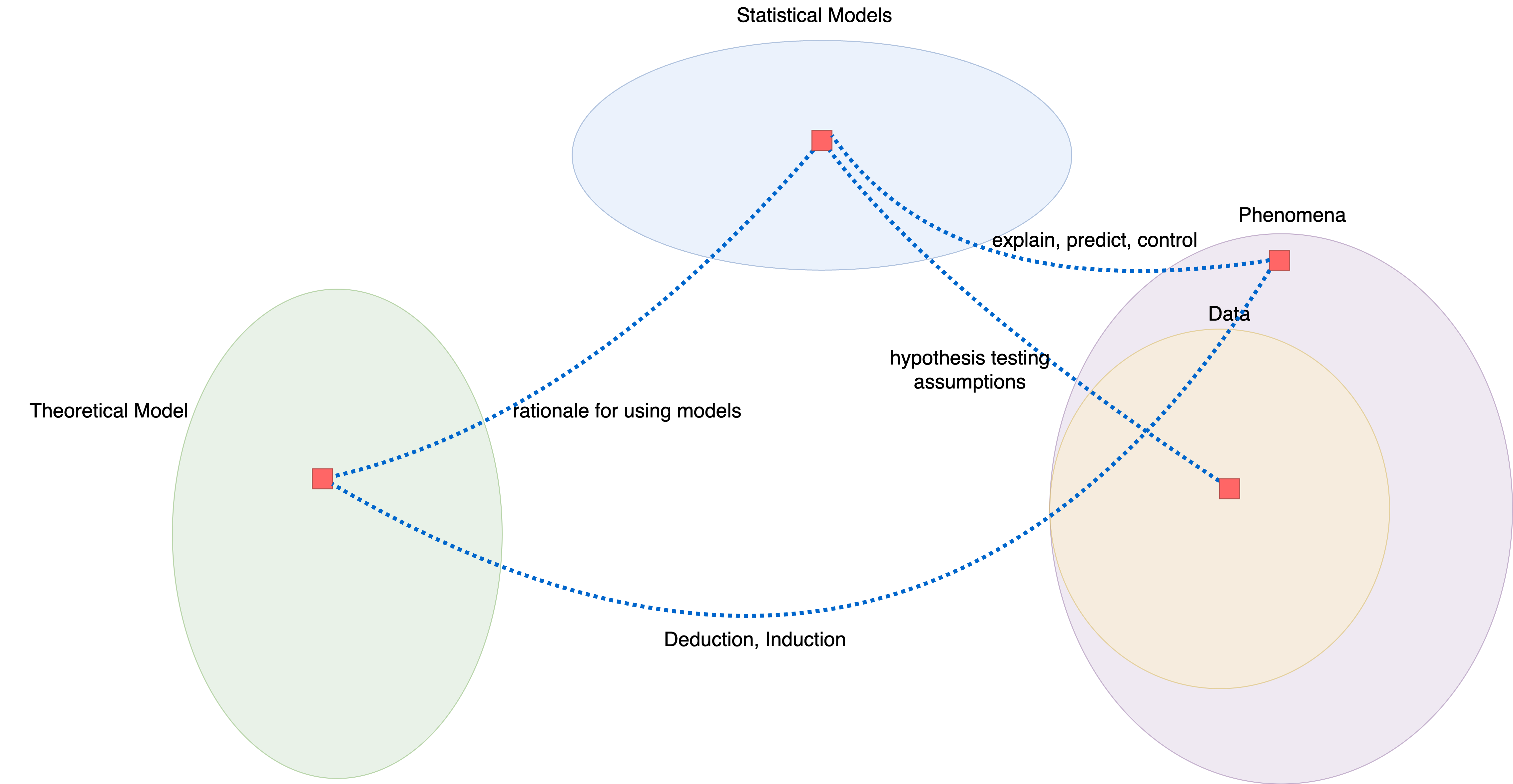
Theories are tools that can explain, predict, and control phenomena. They also exist on a spectrum from strong to weak depending on the degree to which they can explain, predict, and control phenomena. Typically, a theoretical model is related to the data-generating process — how data are generated, which is unknown a priori. We can link theory to data by using statistical modeling that imposes assumptions on the data. However, the statistical models themselves cannot be used to measure how strong or weak the theory is.
Relationships among theory, statistical model, and data
2.1 Community Detection Algorithm
Numerous prior studies have compared different community detection methods in varied network structure (Gates et al., 2016; Yang et al., 2016). In the framework of latent factor analysis or psychometric network, Christensen et al. (2024) recently conducted a Monte Carlo simulation study comparing various node community detection algorithms. To interpret the results, Christensen et al. (2024) even created a Shiny App to interactively present the results.
Table 1: Different types of community detection algorithms
Table 1 shows the list of community detection algorithms and their features. In the framework of psychometric assessment (< 50 nodes, balanced item number per factor), the best-performing algorithms are GLASSO with unidimensional adjustment, Louvain, Fast-greedy, Walktrap, and parallel analysis. The evaluation criteria include:
The percentage of correct number of factors (PC)
Mean absolute error (MAE; the average absolute deviation away from the correct number of factors)
Mean bias error (MBE; the average deviation away from the correct number of factors)
Assume N is the total number of simulated sample data sets (Replication), K is the population number of factors/communities, and \hat{K} is the estimated number of factors/communities. \mathbb{I}(\cdot) is the indicator function so that \mathbb{I}(\hat{K}, K) = 1 if \hat{K} = K and \mathbb{I}(\hat{K}, K) = 0 otherwise. The three evaluation criteria are defined as:
## K is a vector of population number of factors with the length of number replications## K_hat is a vector of estimate number of factors with the length of number replicationscal_pc <-function(K, K_hat) { N <-length(K) pc <-sum(K_hat == K) / Nreturn(pc)}cal_mae <-function(K, K_hat) { N <-length(K) mae <-sum(abs(K_hat - K)) / Nreturn(mae)}cal_mbe <-function(K, K_hat) { N <-length(K) mbe <-sum(K_hat - K) / Nreturn(mbe)}
3 Example: Accuracy and Stability for Fast Greedy and Walktrap
For illustration, we can examine the differences in accuracy and stability between the fast-greedy method and the walktrap method due to the sampling error. The sample data is the Big Five questionnaire dataset (N = 2800). The bootstrapping resampling method with 100 replications and 10% total sample size is used for the analysis.
For evaluation criteria, the standard deviation (SD) for the two methods was used to examine stability; PC, MAE, and MBE for the two methods were used to examine accuracy.
Community Detection for Bootstrapping Resampled Samples
library(igraph) # For community detectionlibrary(foreach) # For parallel computinglibrary(doParallel) # For core registration# Load bfi data from psych package:Data <- bfi |>select(A1:A5, C1:C5, E1:E5, N1:N5, O1:O5) |>na.omit()ten_perc_N =floor(nrow(Data) /10) # Number of cases for 10% sample sizeN_replications <-100# Number of bootstrapping resampling# Function to get the number of communities by fast-greedy and walktrapget_resampling_community_n <- \(dat, i, size) {set.seed(1234+ i) sampled_cases <- dat[sample(x =1:nrow(dat), size = size), ]# Define variables: vars <-names(dat)# Saturated estimation: mod_sparsed <-ggm(sampled_cases, vars = vars) |>runmodel() |>stepup() |>prune()## Get edge weights omega_mat <-getmatrix(mod_sparsed, "omega")## Convert to igraph object from adjcent matrix ggm_igraph <-graph_from_adjacency_matrix(adjmatrix =abs(omega_mat), weighted =TRUE, mode ="undirected")## Apply Walktrap / Fast Greedy Community Detection Algoritm ggm_wt <-cluster_walktrap(ggm_igraph) ggm_fg <-cluster_fast_greedy(ggm_igraph)## Get number of detected communities return(c(K_wt =length(ggm_wt), K_fg =length(ggm_fg),size = size, seed = (1234+ i)) )}cl <-makePSOCKcluster(detectCores() -1)registerDoParallel(cl)res <-foreach(i =1:N_replications, .packages =c("psychonetrics", "igraph"),.combine ="rbind") %dopar%get_resampling_community_n(dat = Data, i = i, size = ten_perc_N)stopCluster(cl)
Overall, the fast-greedy method performs better than the walktrap method given its higher value of PC and lower absolute values of MAE and MBE across 100 bootstrapping re-sampling iterations with the \frac{1}{10} sample size. The fast-greedy is also more stable than the walktrap given smaller variability (\mathrm{SD_{FG}}=.65; \mathrm{SD_{WT}}=1.13).
3.1 Sample Size Effect on Community Detection
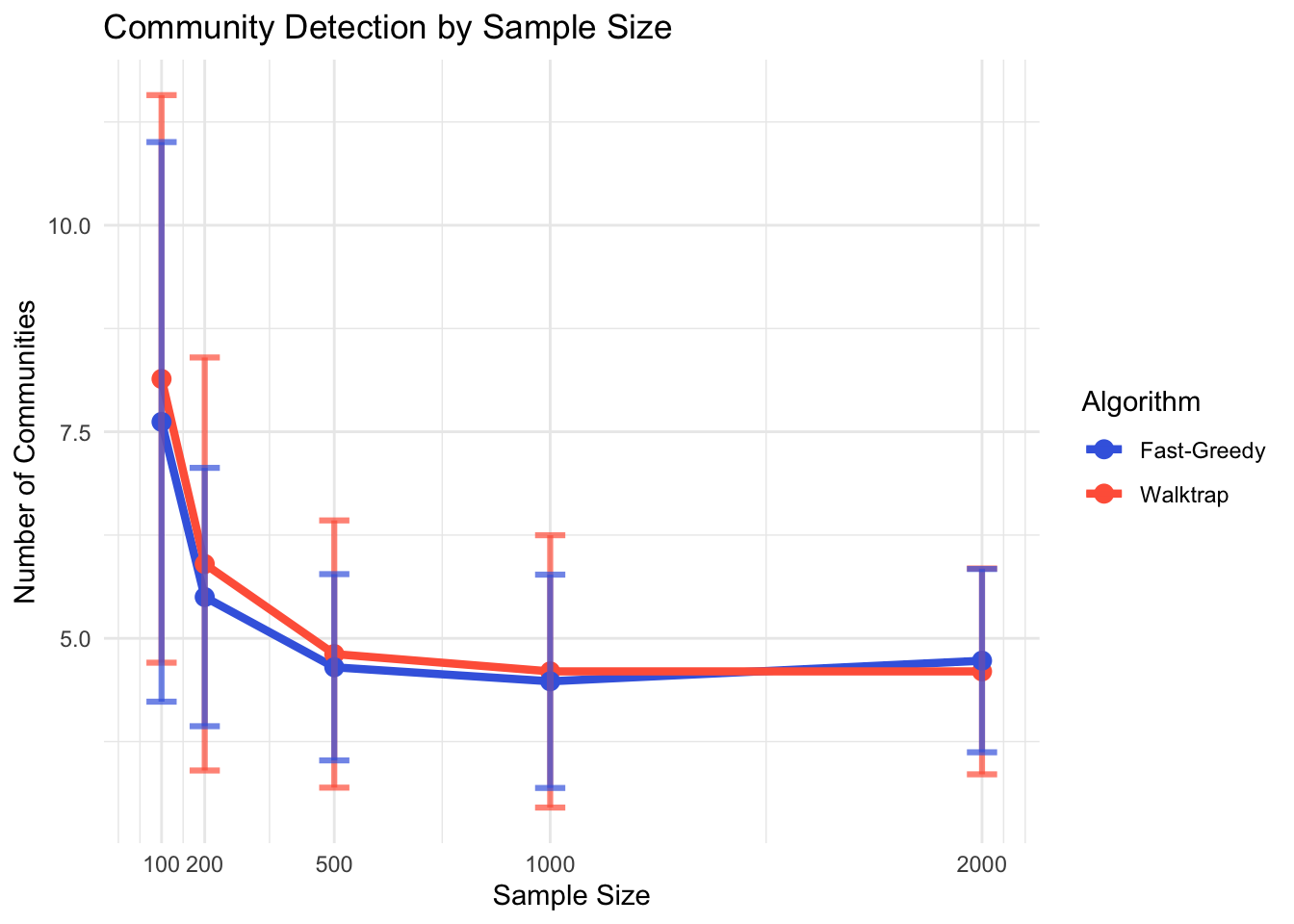
We can further examine the effect of sample size on the community detection. The sample sizes are 100, 200, 500, 1000, and 2000. The bootstrapping resampling method with 100 replications is used for variability in each condition.
As shown in Figure 1, for both methods, as sample size gets larger, the number of communities detected by both methods tends to align with the theoretical number of communities, K = 5. From N = 100 to N = 200 has strong increase in the accuracy of the number of communities detected, while from N = 200 to N = 500 has moderate improvement in the number of communities detected. After N = 500, the number of communities detected is stable.
4 Take-Away Notes
TipKey Findings
1. Community ≠ Clustering (by eye)
Visual inspection of network structure is an unreliable way to identify communities. Nodes that appear to cluster visually may not form statistically coherent communities, and true communities can be invisible in dense or large networks. Formal community detection algorithms should replace informal visual judgment.
2. Community detection accuracy depends heavily on the algorithm
Among the algorithms reviewed, fast-greedy and walktrap are two of the most commonly used in psychometric network research. Fast-greedy consistently outperforms walktrap in both accuracy (higher PC, lower MAE/MBE) and stability (smaller SD across bootstrap resamples) in the Big Five dataset, suggesting it is the safer default when the number of factors is unknown.
3. Small samples mislead community detection
Both fast-greedy and walktrap produce substantially wrong community counts at N < 200. The accuracy improves steeply from N = 100 to N = 200, and stabilizes around N = 500. Researchers working with small samples should treat community detection results with extra caution — or at minimum report bootstrap stability statistics alongside the point estimate.
4. Exploratory vs. confirmatory framing matters
When theory dictates which nodes should belong together (e.g., DSM-defined syndromes), a confirmatory network approach (pre-specified communities) is more defensible than an exploratory one. Exploratory community detection is valuable for hypothesis generation, but it inflates the risk of over-interpreting data-driven groupings as meaningful constructs.
5. Bridge symptoms sit between communities — not within them
The theoretical value of community detection in psychopathology research is not just to identify what goes together, but to locate bridge symptoms connecting different communities. These bridge nodes (e.g., a symptom shared by depression and anxiety syndromes) are prime candidates for intervention targets, since disrupting a bridge can potentially destabilize multiple symptom clusters simultaneously.
Andersson, B., & Xin, T. (2021). Estimation of latent regression item response theory models using a second-order laplace approximation. Journal of Educational and Behavioral Statistics, 46(2), 244–265. https://doi.org/10.3102/1076998620945199
Blondel, V. D., Guillaume, J.-L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10), P10008. https://doi.org/10.1088/1742-5468/2008/10/P10008
Borsboom, D. (2002). The structure of the DSM. Archives of General Psychiatry, 59(6), 569–570.
Christensen, A. P., Garrido, L. E., Guerra-Peña, K., & Golino, H. (2024). Comparing community detection algorithms in psychometric networks: A monte carlo simulation. Behavior Research Methods, 56(3), 1485–1505. https://doi.org/10.3758/s13428-023-02106-4
Clauset, A., Newman, M. E. J., & Moore, C. (2004). Finding community structure in very large networks. Physical Review E, 70(6), 066111. https://doi.org/10.1103/PhysRevE.70.066111
Cramer, A. O. J., Waldorp, L. J., Maas, H. L. J. van der, & Borsboom, D. (2010). Comorbidity: A network perspective. Behavioral and Brain Sciences, 33(2-3), 137–150. https://doi.org/10.1017/S0140525X09991567
Du, X., Skjerdingstad, N., Freichel, R., Ebrahimi, O. V., Hoekstra, R. H. A., & Epskamp, S. (2024). Moving from exploratory to confirmatory network analysis: An evaluation of SEM fit indices and cutoff values in network psychometrics. https://doi.org/10.31234/osf.io/d76ab
Fried, E. I. (2020). Lack of theory building and testing impedes progress in the factor and network literature. Psychological Inquiry, 31(4), 271–288. https://doi.org/10.1080/1047840X.2020.1853461
Gates, K. M., Henry, T., Steinley, D., & Fair, D. A. (2016). A monte carlo evaluation of weighted community detection algorithms. Frontiers in Neuroinformatics, 10. https://doi.org/10.3389/fninf.2016.00045
Girvan, M., & Newman, M. E. J. (2002). Community structure in social and biological networks. Proceedings of the National Academy of Sciences, 99(12), 7821–7826. https://doi.org/10.1073/pnas.122653799
Goekoop, R., & Goekoop, J. G. (2014). A network view on psychiatric disorders: Network clusters of symptoms as elementary syndromes of psychopathology. PLOS ONE, 9(11), e112734. https://doi.org/10.1371/journal.pone.0112734
Massara, G. P., Di Matteo, T., & Aste, T. (2017). Network filtering for big data: Triangulated maximally filtered graph. Journal of Complex Networks, 5(2), 161–178. https://doi.org/10.1093/comnet/cnw015
Newman, M. E. J. (2006). Modularity and community structure in networks. Proceedings of the National Academy of Sciences, 103(23), 8577–8582. https://doi.org/10.1073/pnas.0601602103
Pons, P., & Latapy, M. (2006). Computing communities in large networks using random walks. Journal of Graph Algorithms and Applications, 10(22), 191–218. https://doi.org/10.7155/jgaa.00124
Raghavan, U. N., Albert, R., & Kumara, S. (2007). Near linear time algorithm to detect community structures in large-scale networks. Physical Review E, 76(3), 036106. https://doi.org/10.1103/PhysRevE.76.036106
Rosvall, M., & Bergstrom, C. T. (2008). Maps of random walks on complex networks reveal community structure. Proceedings of the National Academy of Sciences, 105(4), 1118–1123. https://doi.org/10.1073/pnas.0706851105
Yamaguchi, K., & Zhang, J. (2023). Fully gibbs sampling algorithms for bayesian variable selection in latent regression models. Journal of Educational Measurement, 60(2), 202–234. https://doi.org/10.1111/jedm.12348
Yang, Z., Algesheimer, R., & Tessone, C. J. (2016). A comparative analysis of community detection algorithms on artificial networks. Scientific Reports, 6(1), 30750. https://doi.org/10.1038/srep30750
Zhang, J., & Liang, X. (2024). Evaluating general network scoring methods as alternatives to traditional factor scoring methods. https://doi.org/10.31234/osf.io/s3re6